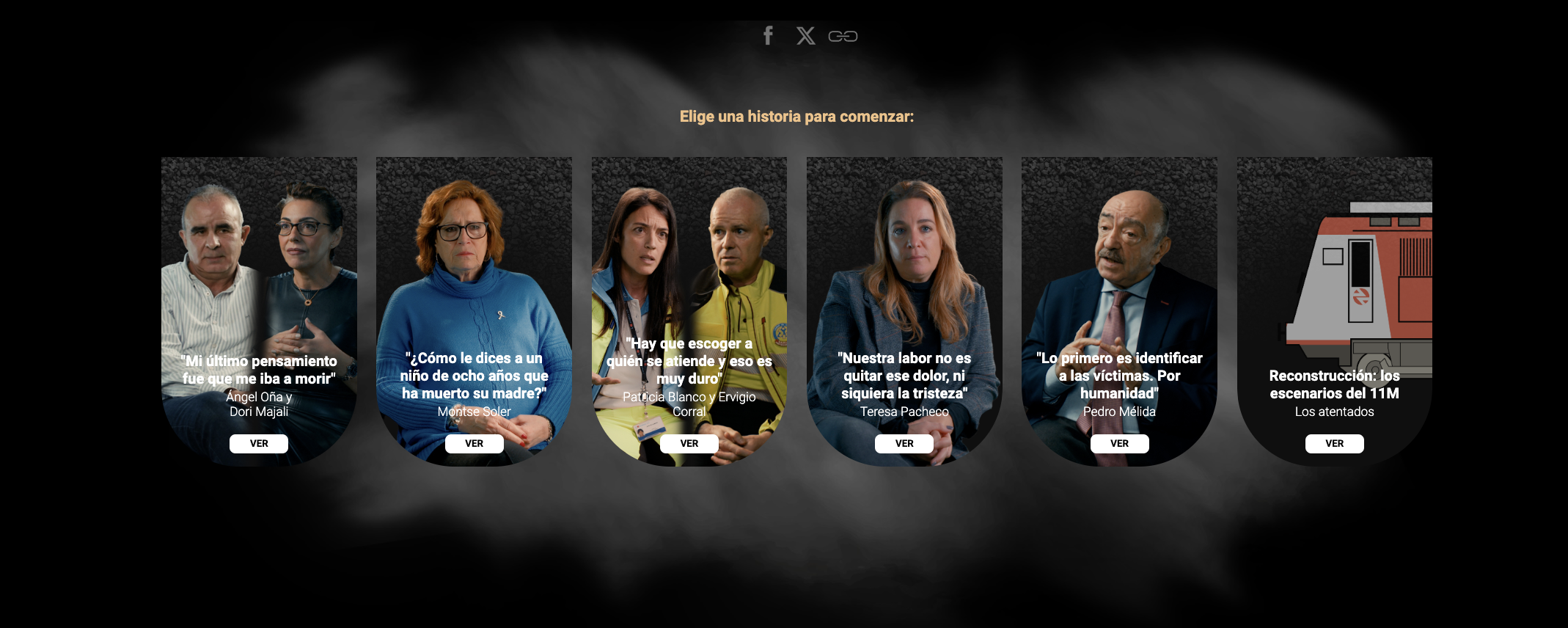
Periodismo de datos
Lo que 15.000 alarmas cuentan de la Guerra de Ucrania
El País
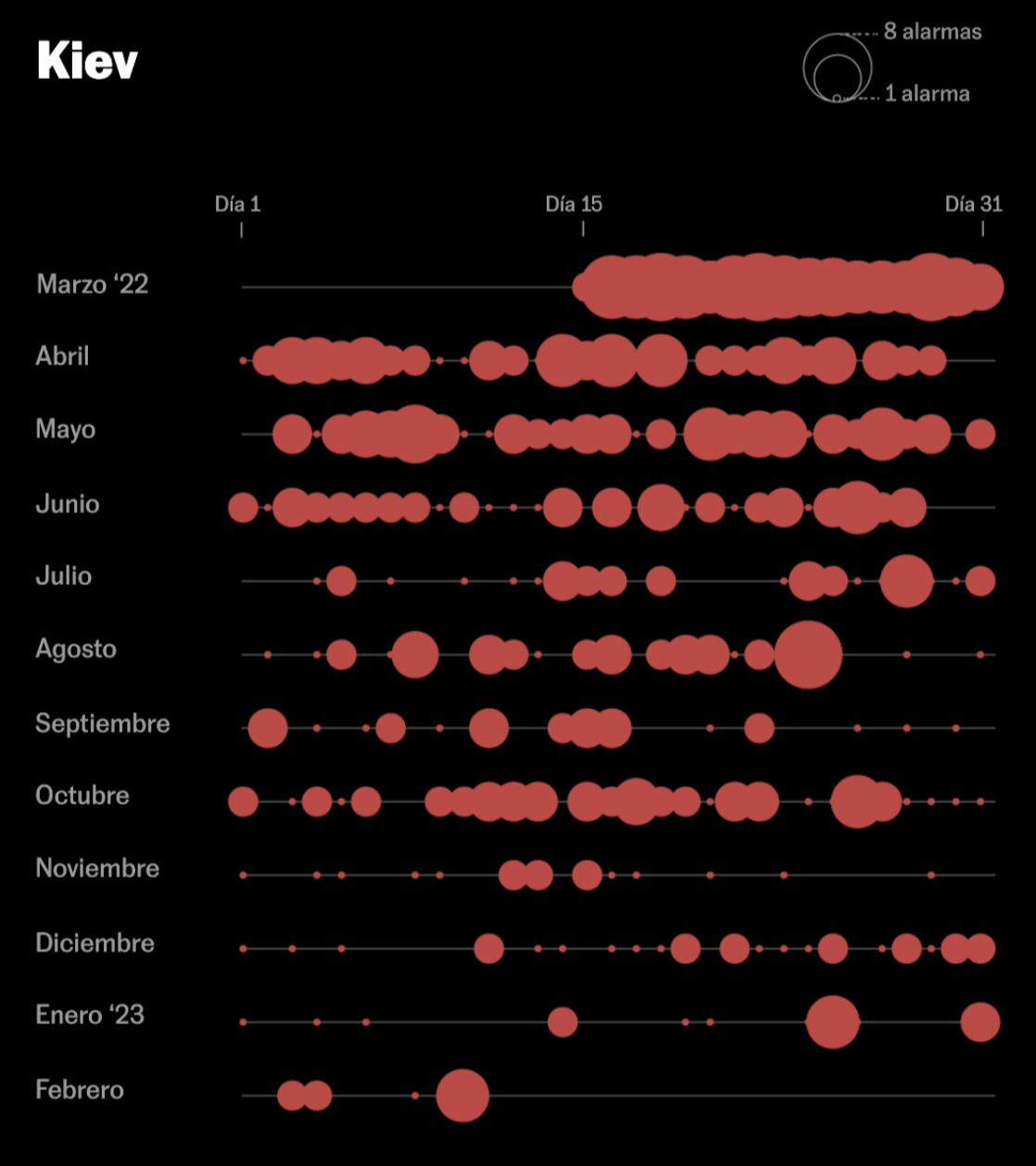
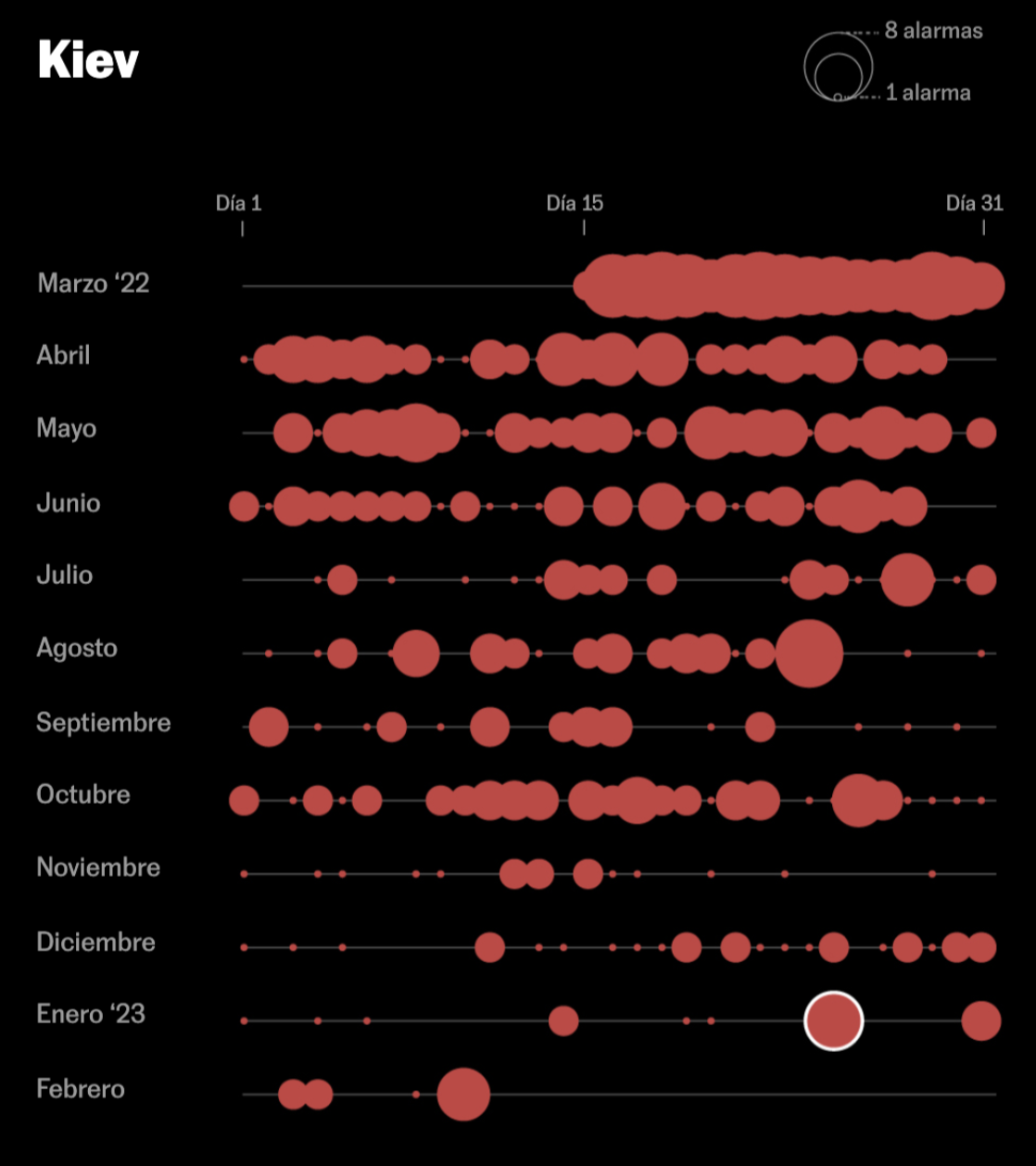
Rusia emprendió el asalto a la capital de Ucrania con brutalidad: hubo más de cien sirenas solo en la segunda quincena de marzo.
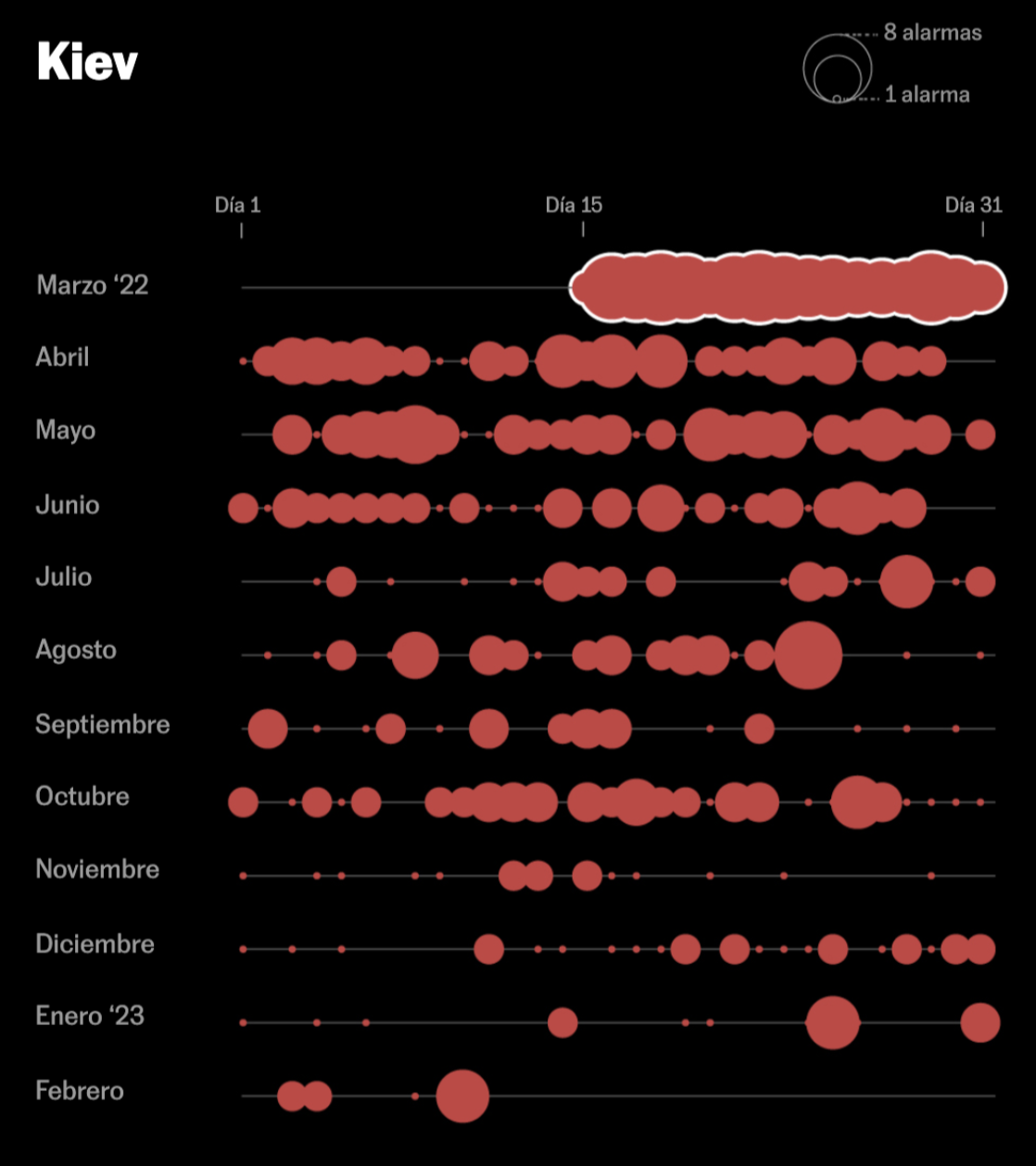
Fracasada la toma de Kiev, y tras un verano con menos ataques, el 8 de octubre, la destrucción del puente que unía Crimea y Rusia provocó una nueva ofensiva del Kremlin.
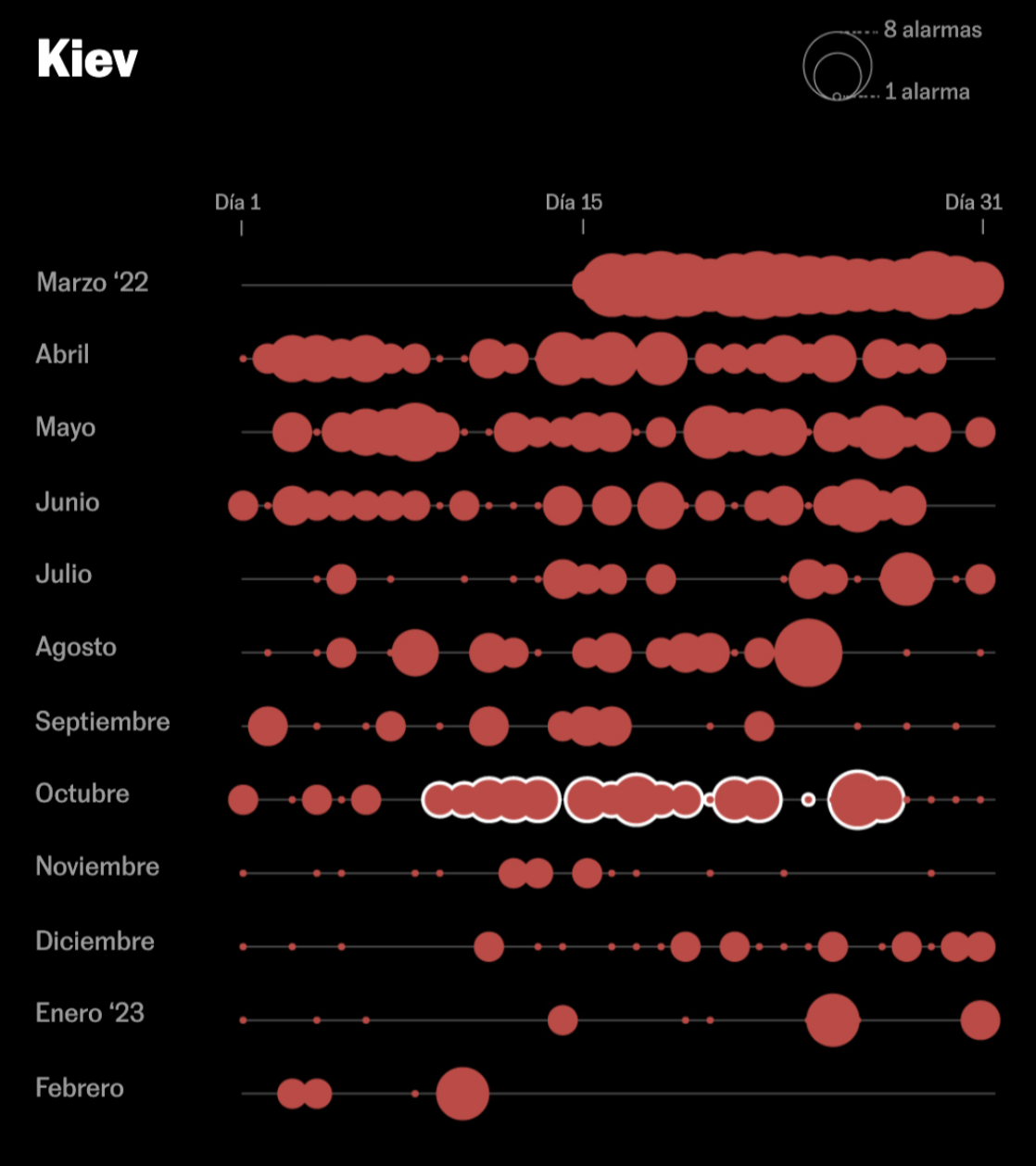
El 25 de enero, solo en Kiev sonaron cinco alarmas que advertían del impacto de los 30 misiles lanzados por Rusia en respuesta al compromiso de EE.UU. y Alemania de enviar tanques a Ucrania.
⚠️ Los datos pueden cambiar tu punto de vista
⚠️ Los datos pueden cambiar tu punto de vista
🚨 Los datos pueden engañarnos
Warning
Correlación NO implica causalidad
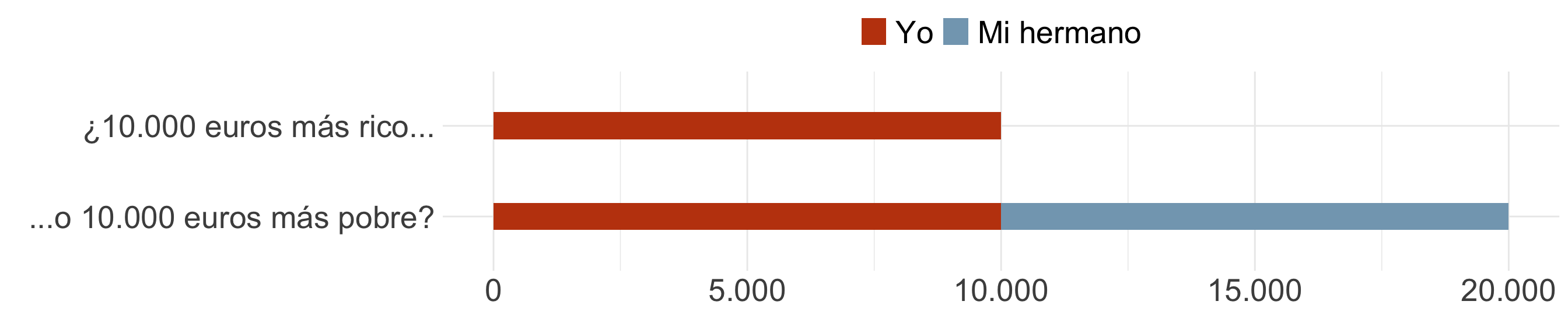
¿Qué es más eficiente?


Xaquín Veira González
Todo es relativo

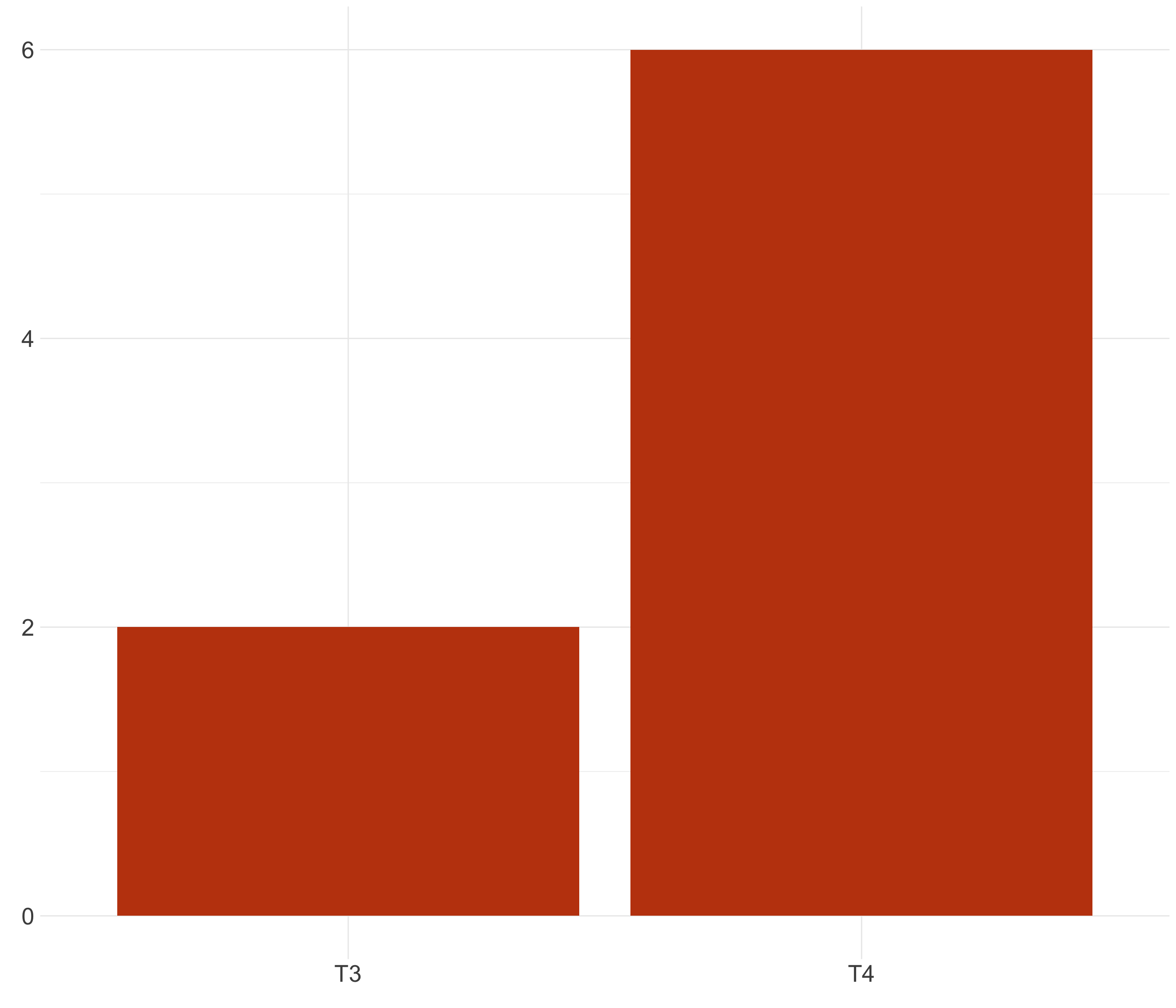
Cuenta la historia completa (I)
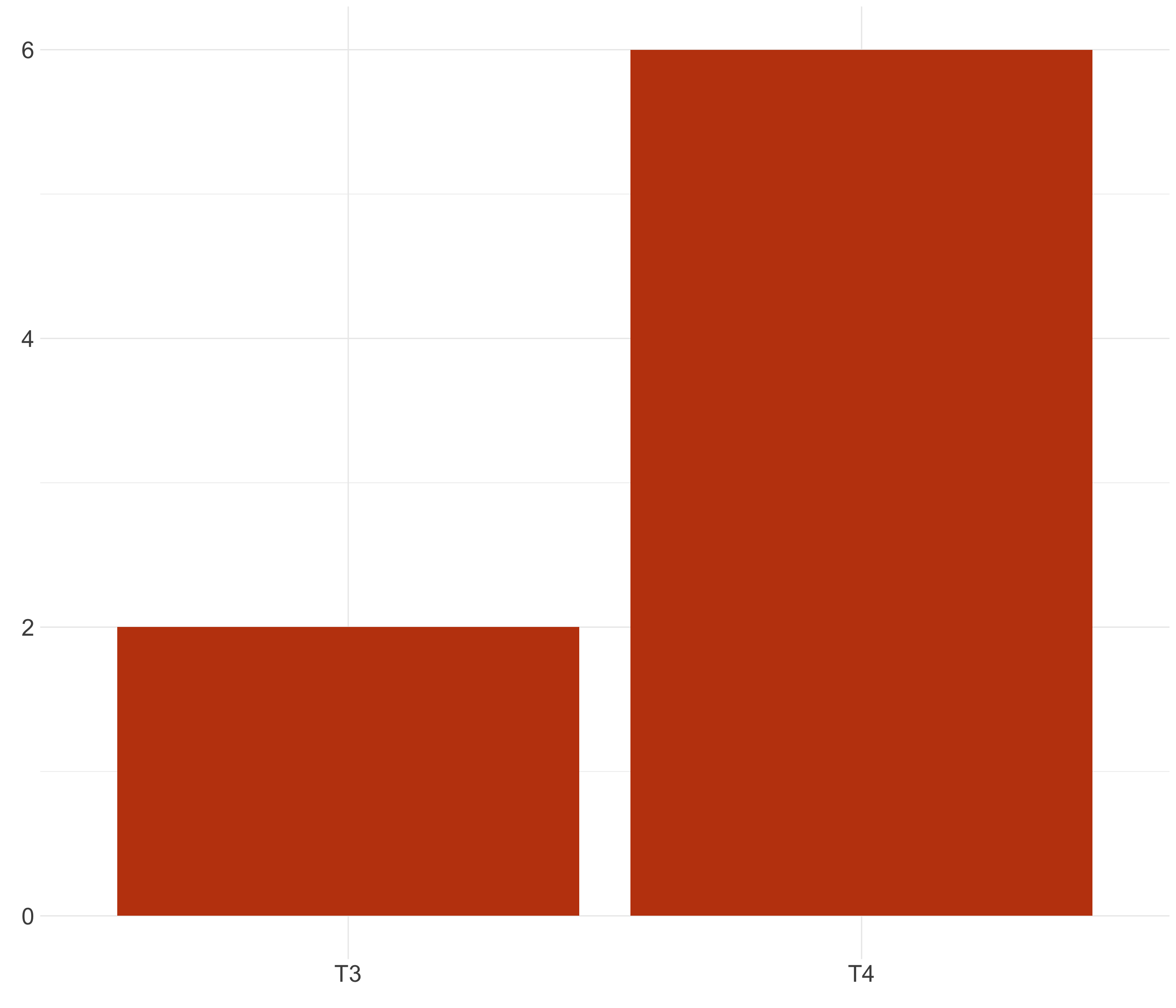
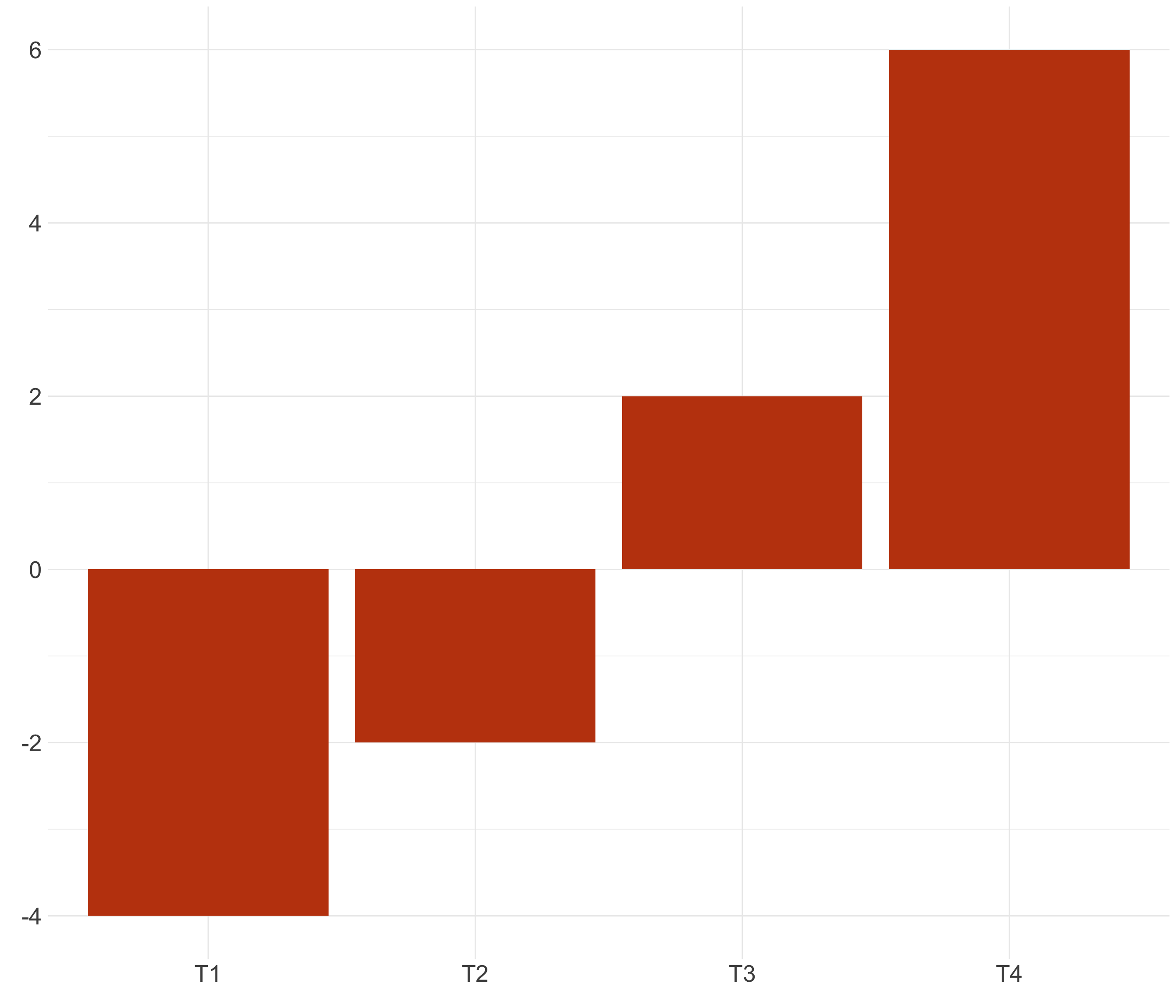
Cuenta la historia completa (II)
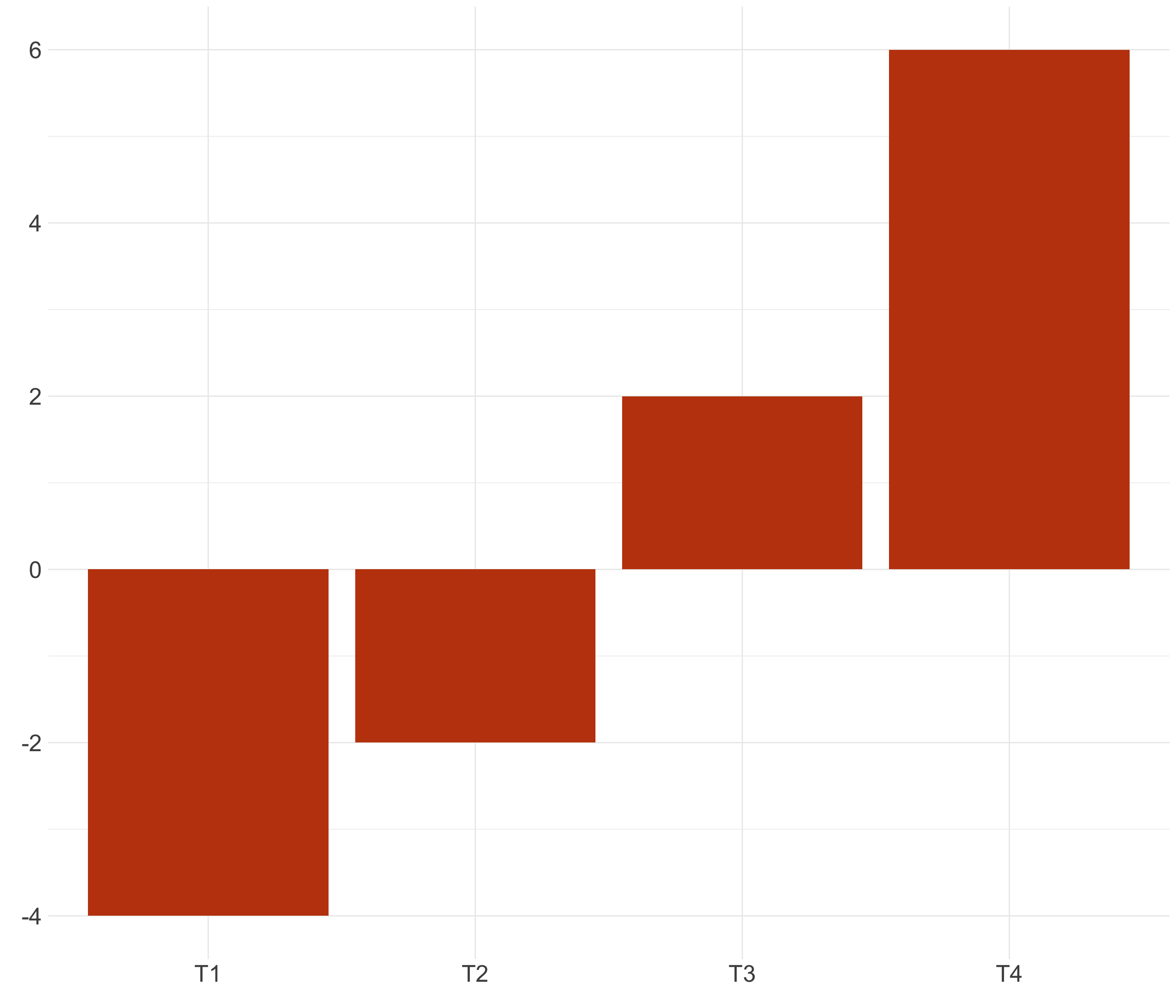
Note
El mensaje debe ser consistente con todos los datos relevantes para la historia
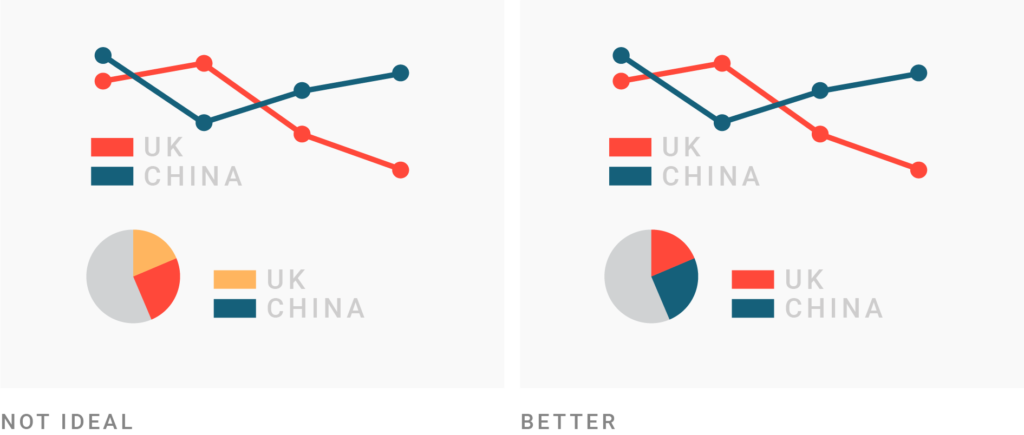
Haz comparaciones justas (I)
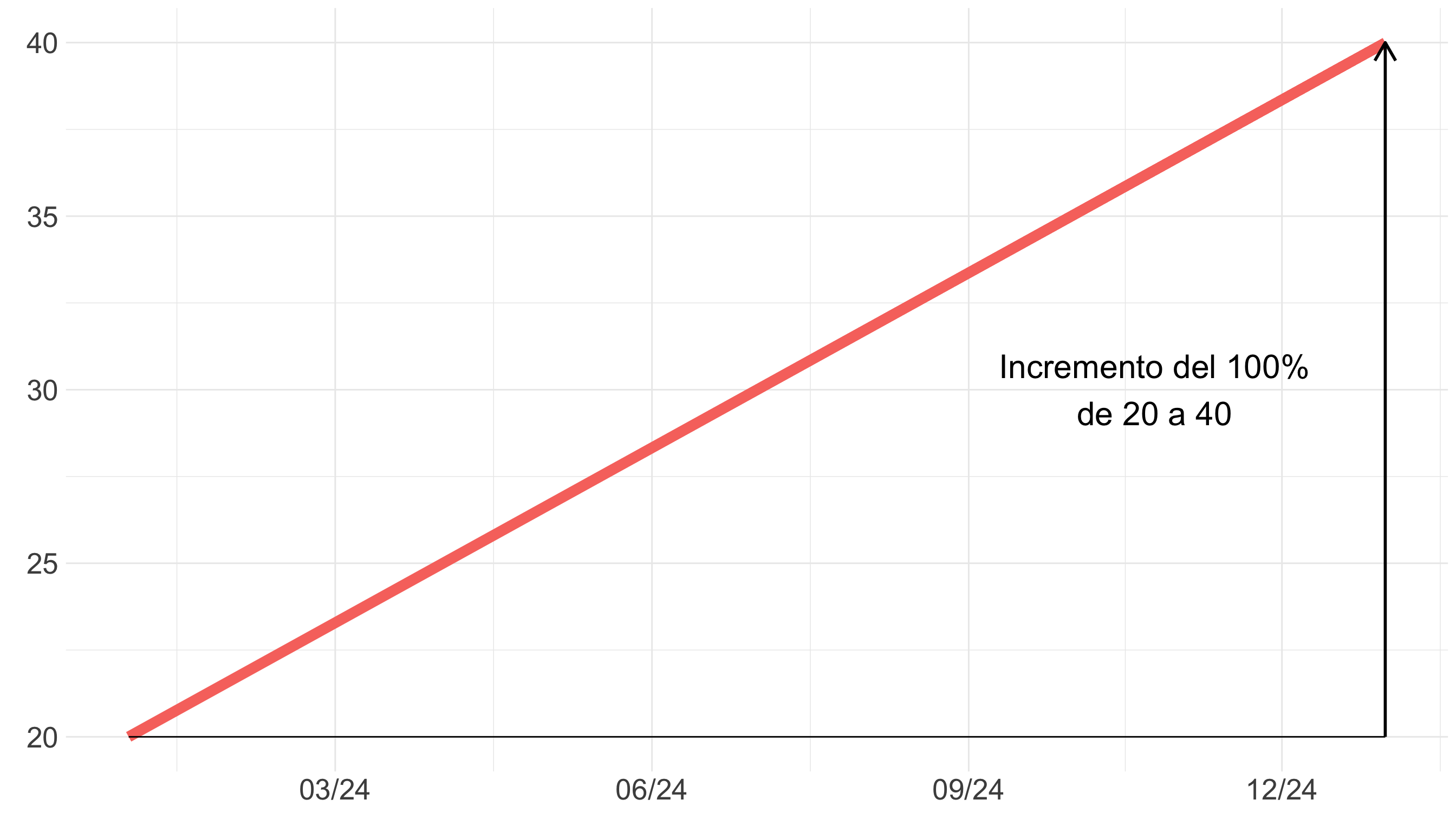
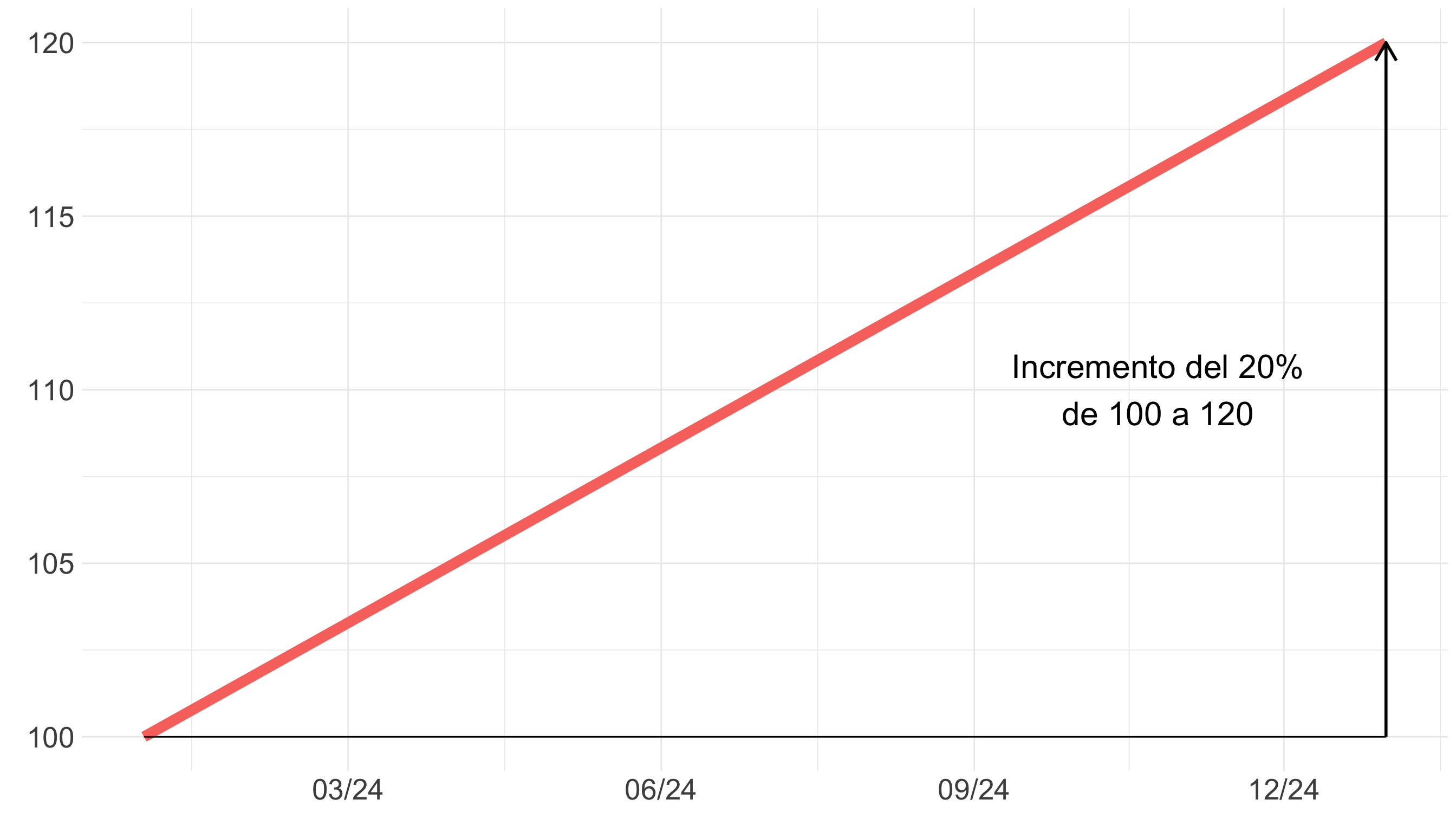
Warning
Si dos gráficos se presentan juntos, se crea una comparación.
Haz comparaciones justas (II)
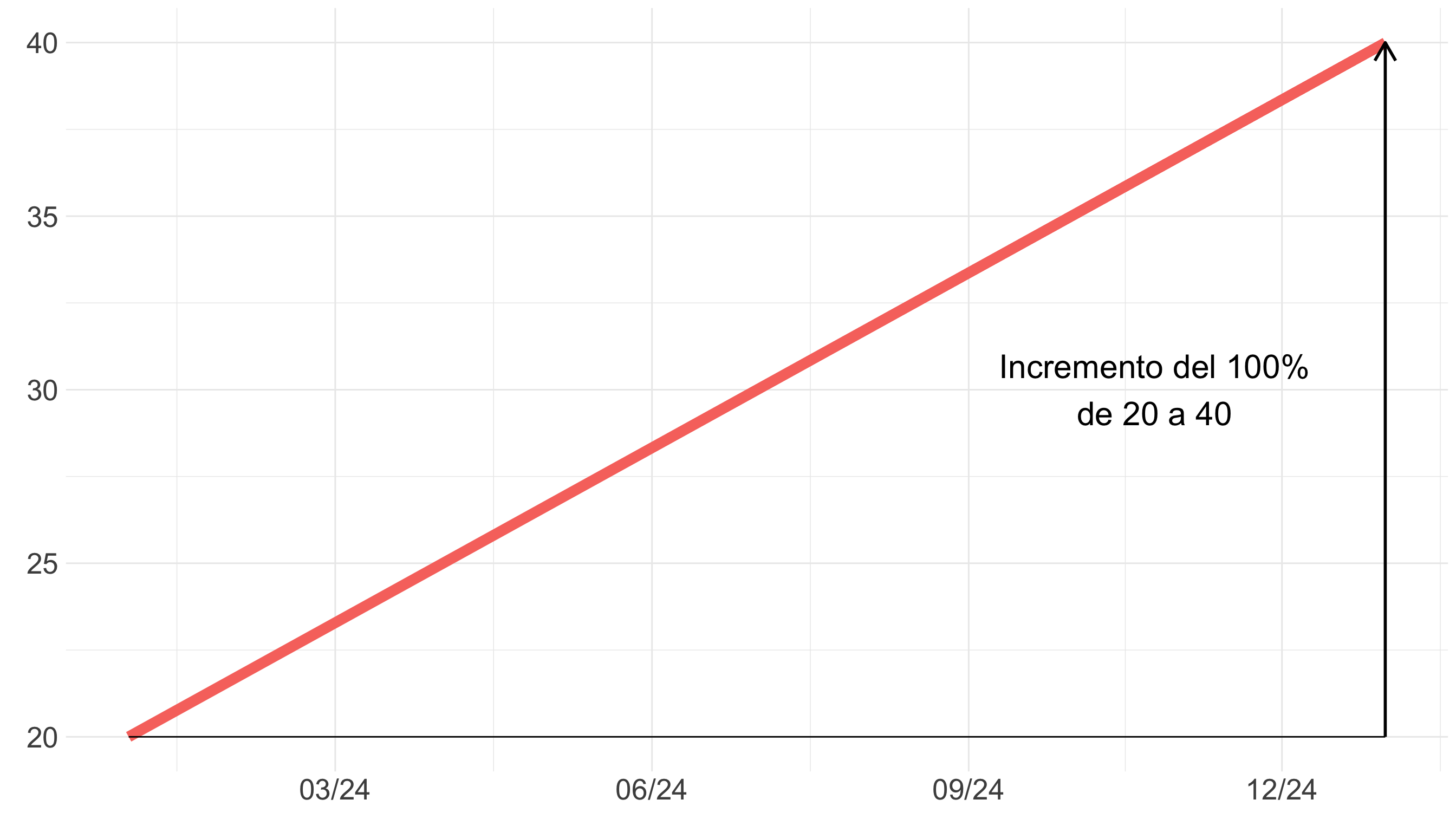
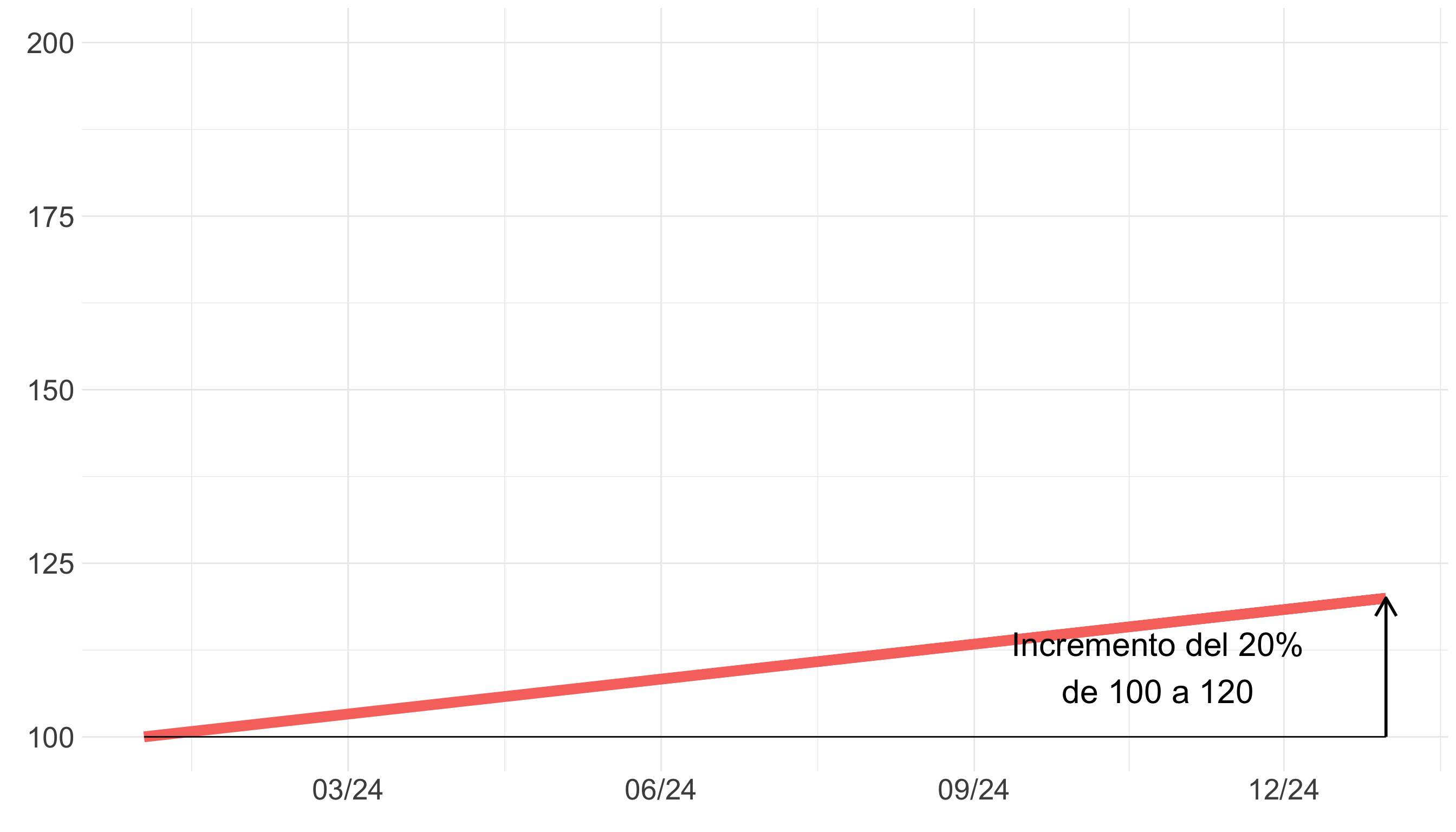
Tip
Usa escalas comparables. El eje de cada gráfico representa el mismo cambio porcentual para que la variación se perciba por la inclinación de las líneas.
Haz comparaciones justas (IV)
| País | Nº tarjetas de crédito (millones) |
|---|---|
| A | 100 |
| B | 300 |
| C | 400 |
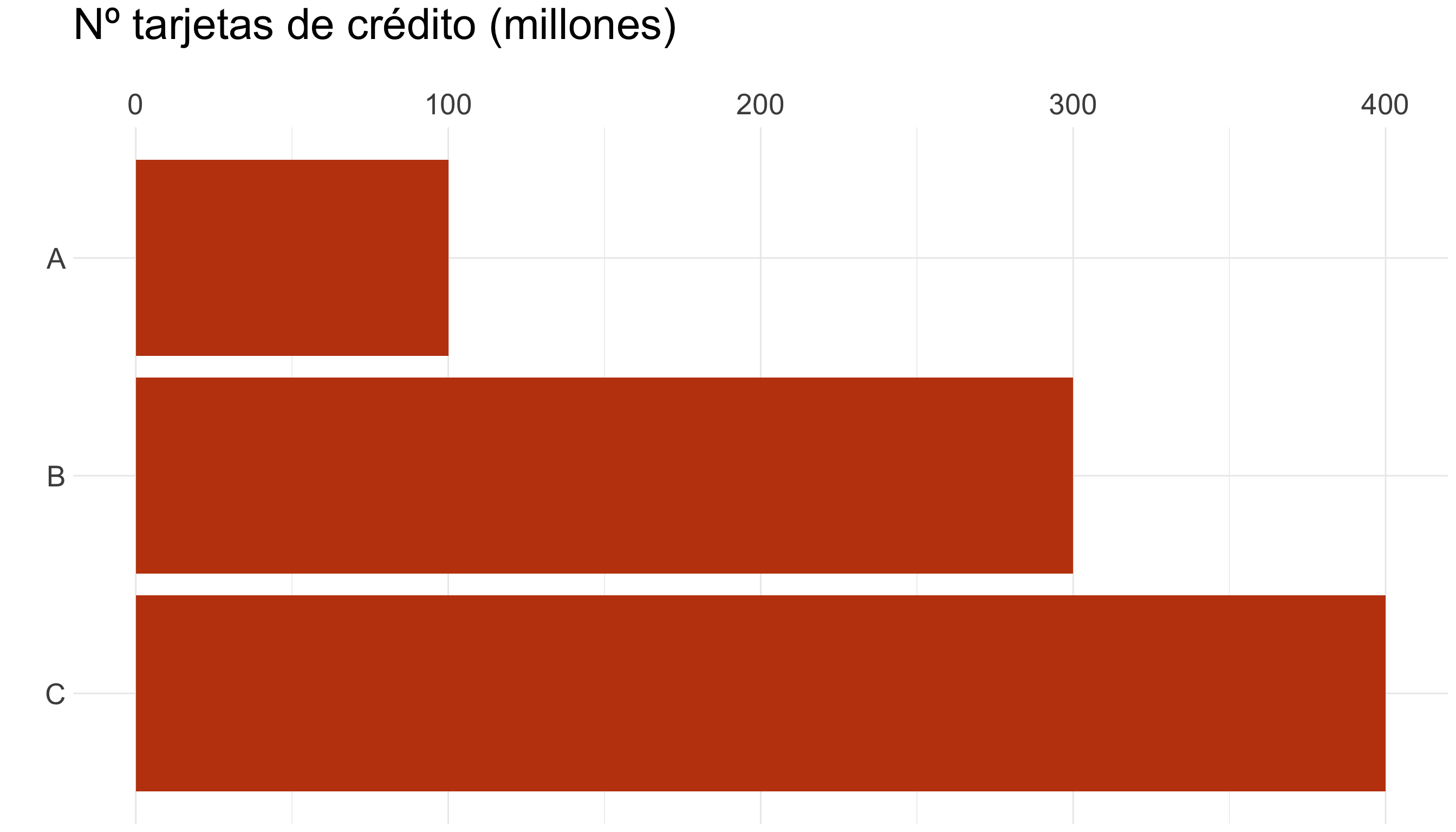
Haz comparaciones justas (V)
| País | Nº tarjetas de crédito (millones) | Población (millones) | Nº tarjetas per cápita |
|---|---|---|---|
| A | 100 | 200 | 0,5 |
| B | 300 | 200 | 1,5 |
| C | 400 | 400 | 1 |
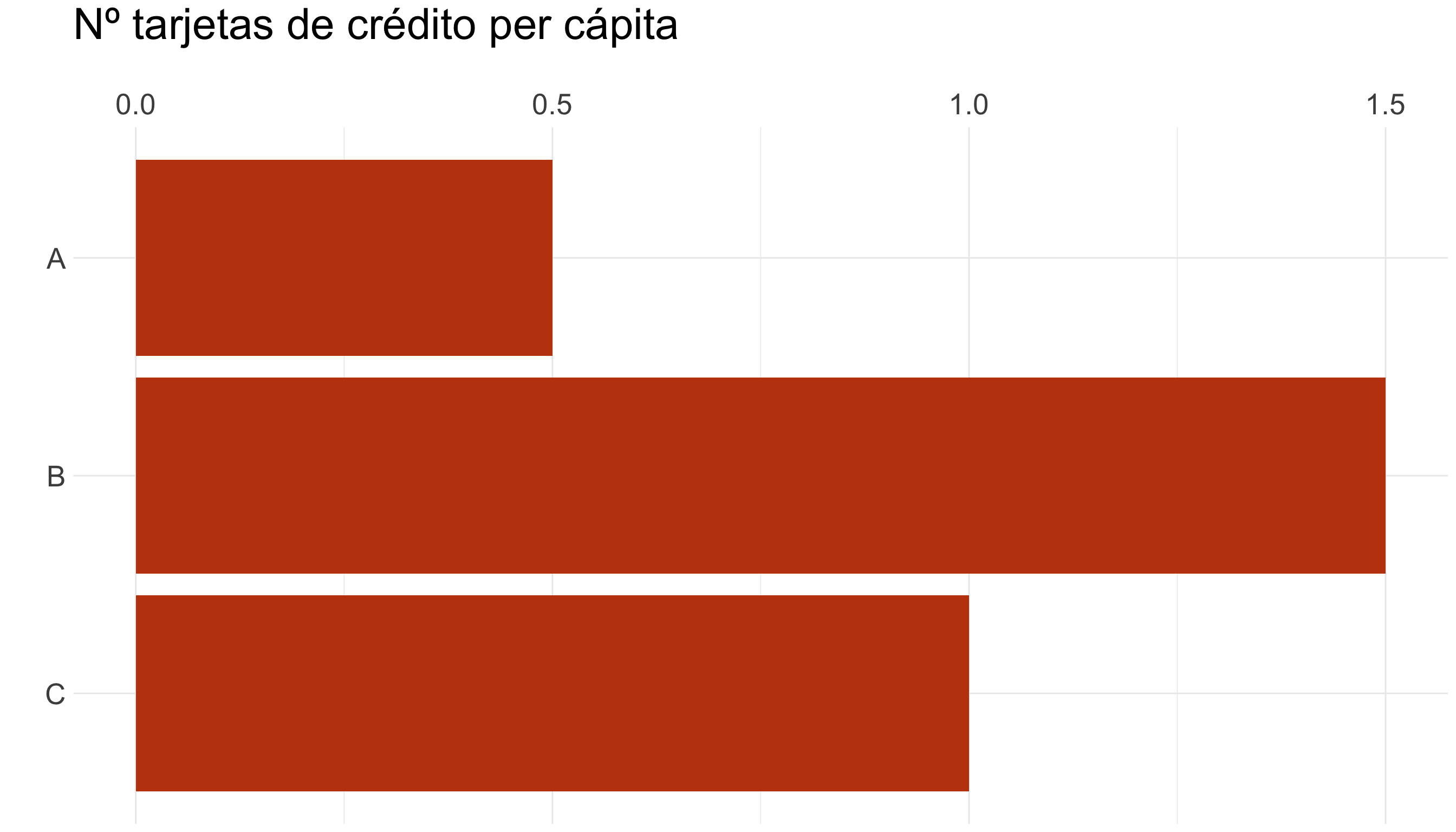
Haz comparaciones justas (VI)
| País | Nº tarjetas de crédito (millones) | Población (millones) | Nº tarjetas per cápita |
|---|---|---|---|
| A | 100 | 200 | 0,5 |
| B | 300 | 200 | 1,5 |
| C | 400 | 400 | 1 |
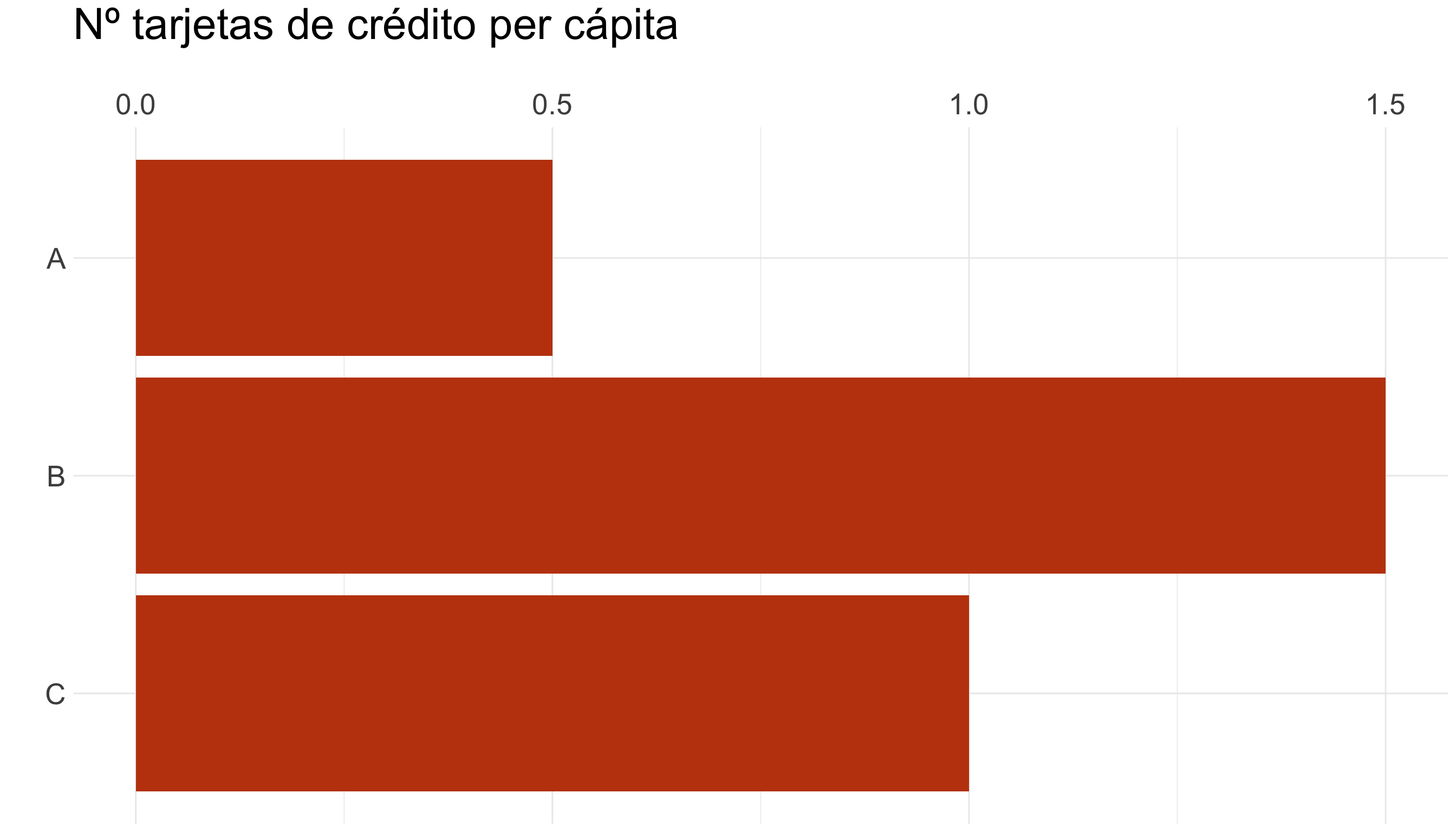
Tip
Si los datos de origen son insuficientes ❌ No le añadas elementos decorativos ✅ Busca fuentes adicionales y ajusta los datos para hacerlos comparables
Los números índices
Los números índices son útiles para realizar comparaciones de magnitudes en el tiempo o en el espacio.
Sirven para medir variaciones y permiten mostrar una evolución temporal o una comparación entre territorios fijando un valor como base.
El IPC no expresa precios en euros, sino las variaciones de esos precios el % para analizar su evolución a lo largo del tiempo.
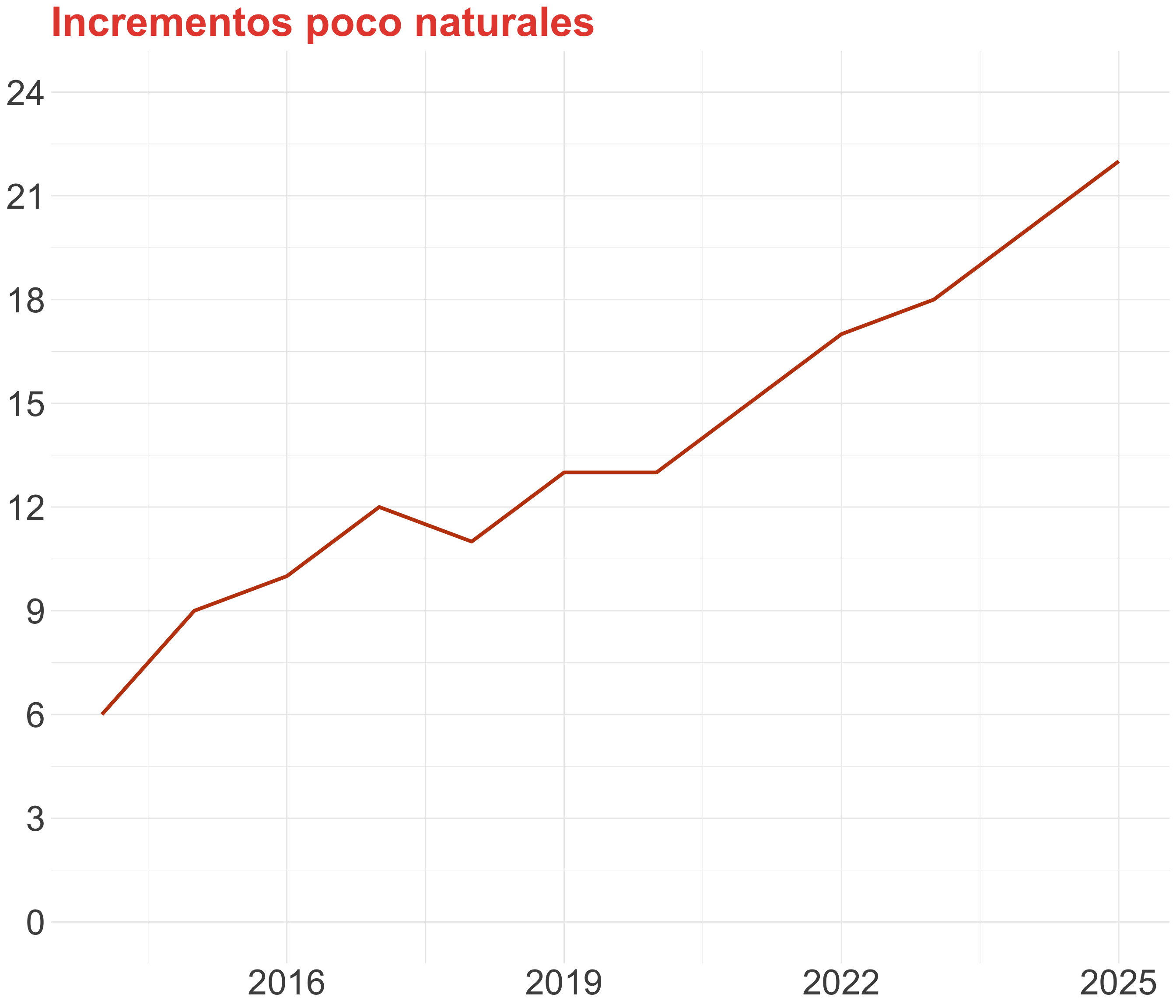
Trata de mostrar la realidad
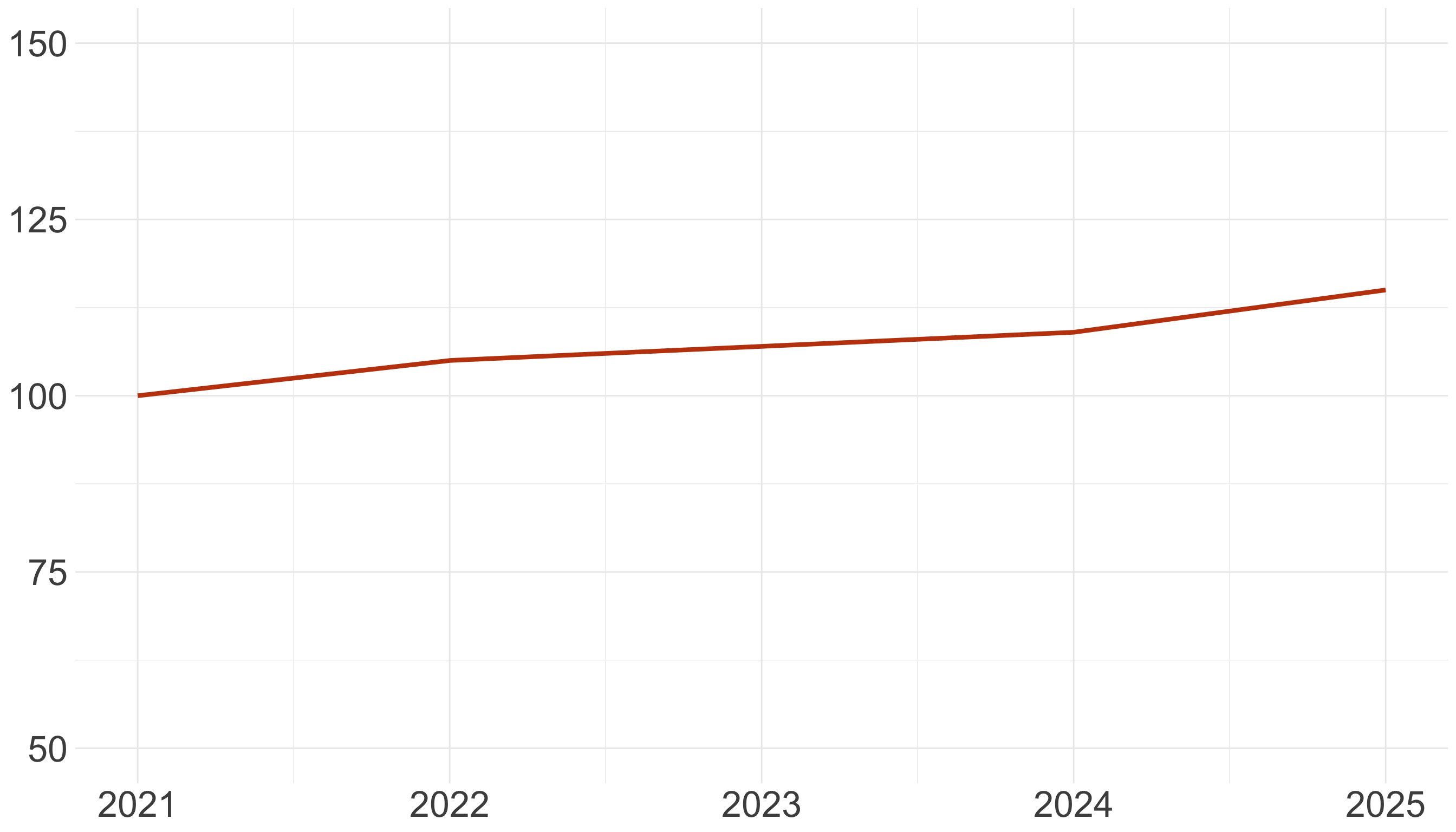
El propósito de un gráfico de líneas es mostrar una tendencia
Elegir una escala que aplana la curva desvirtúa el propósito del gráfico
Exagerar la escala crea un dramatismo que puede ser injusto con la realidad
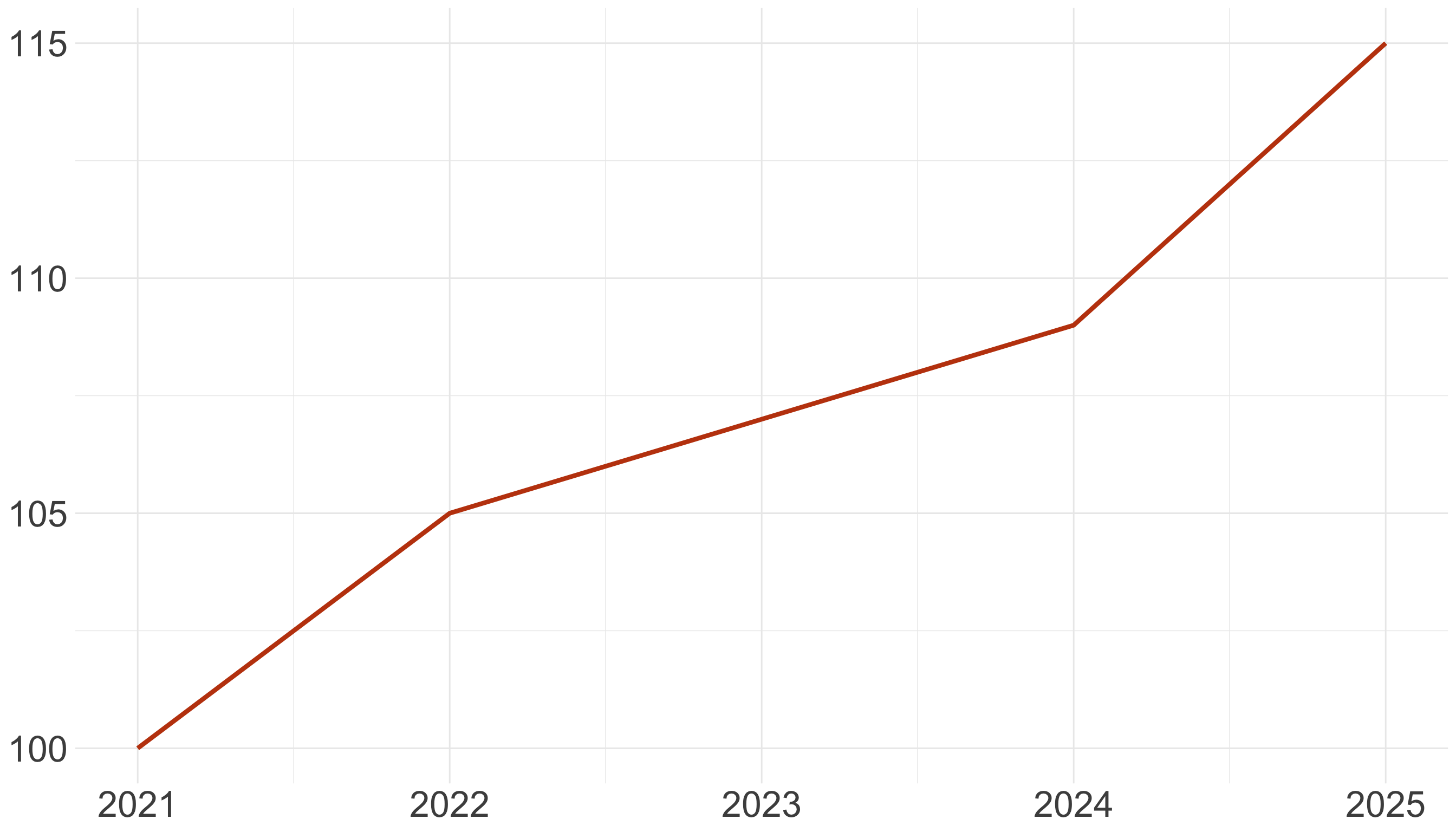
Usa escalas naturales (I)
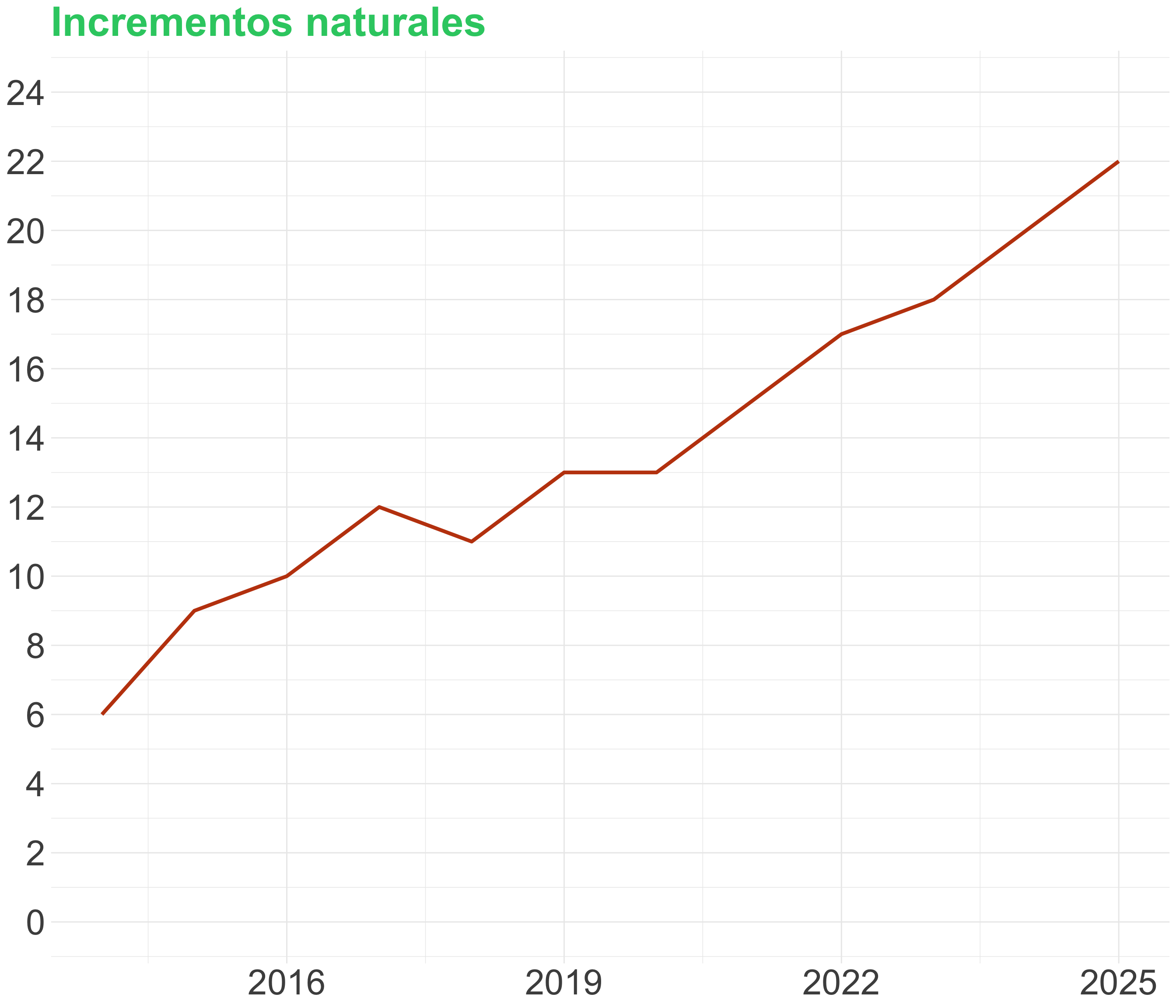
Usa escalas naturales (II)
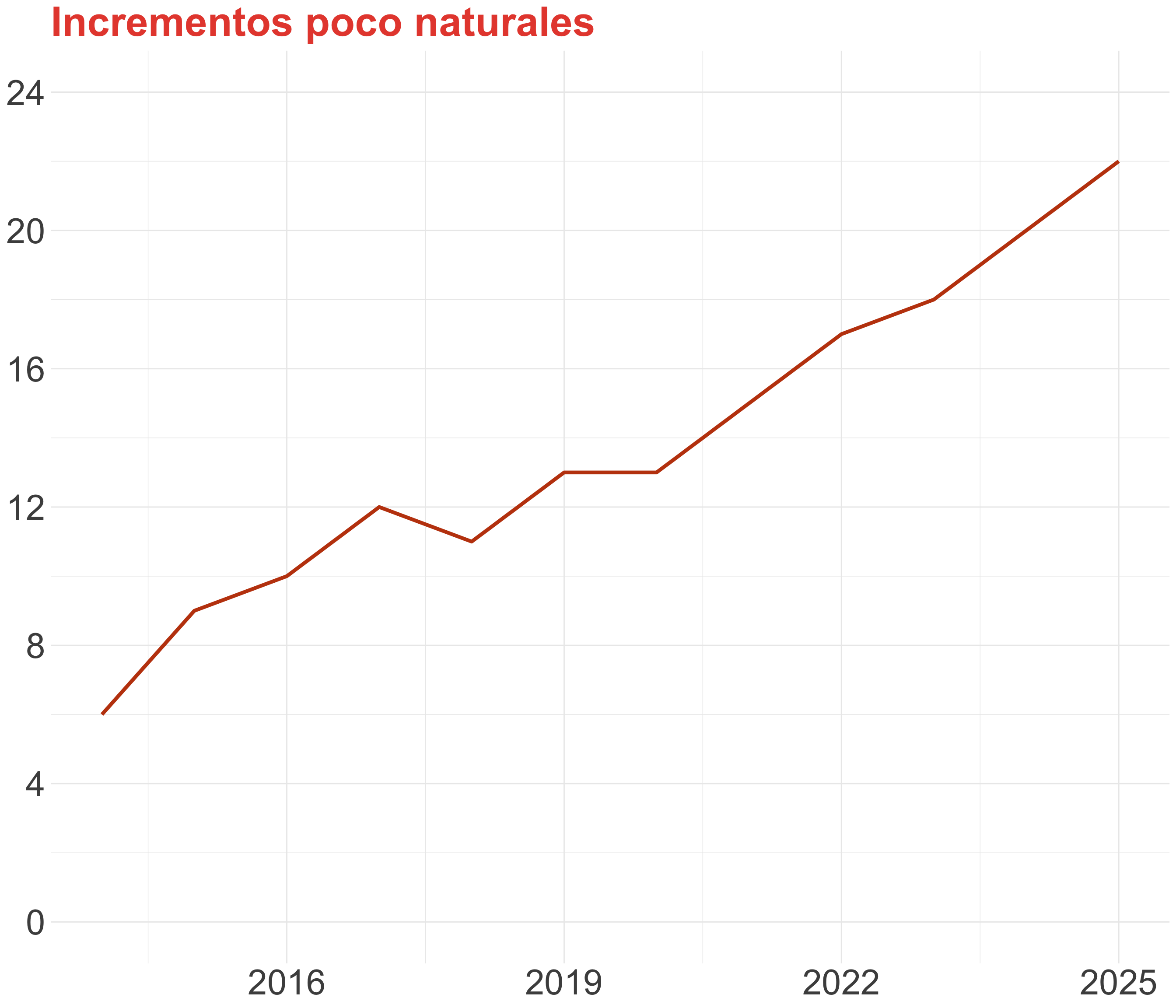
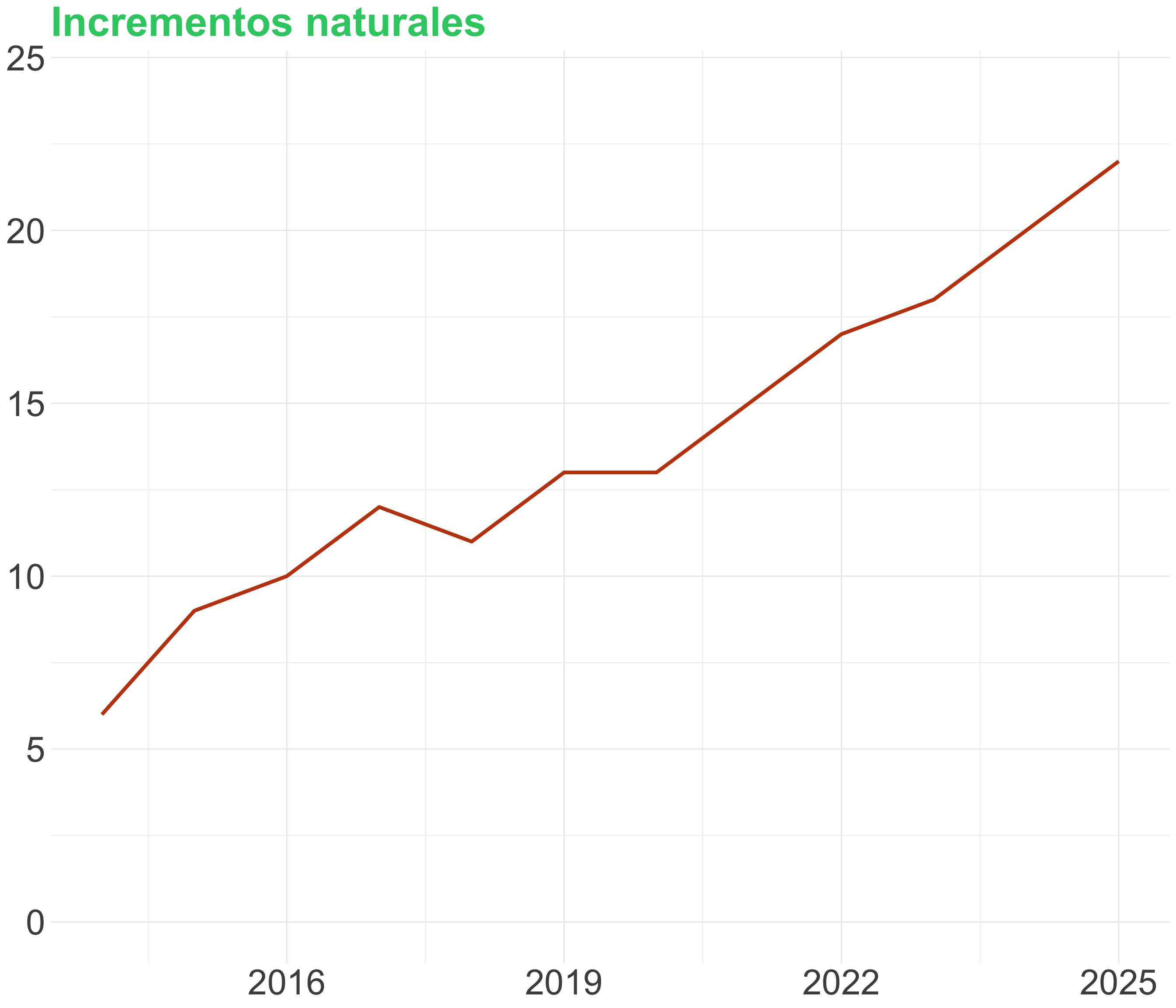
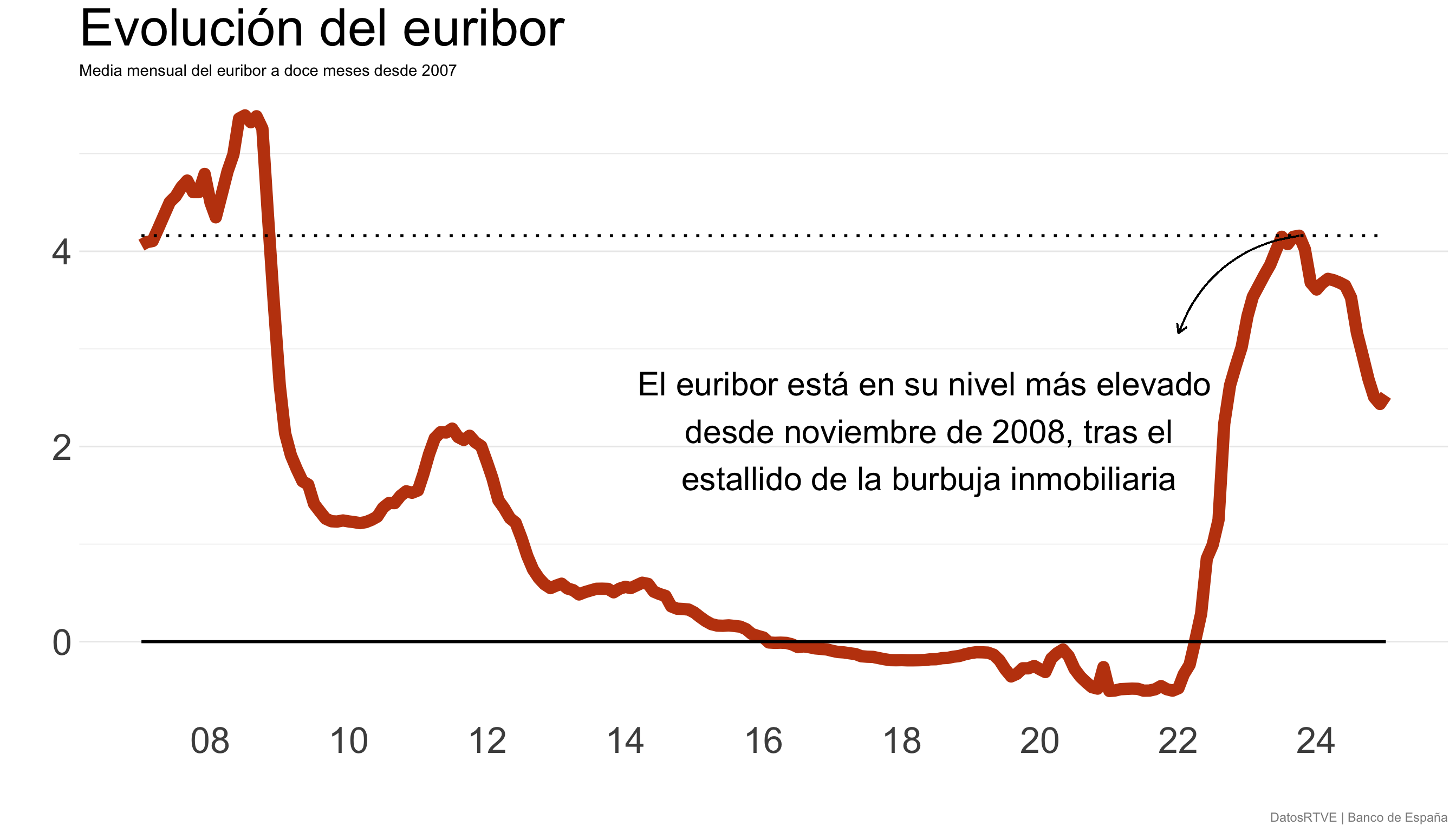
¡Cuidado al truncar el eje! (I)
Los gráficos de línea no siempre necesitan empezar en cero
Aunque hay que incluir la línea de base si los datos están cerca de ella
También es útil mostrar el 0 y el 100% con porcentajes
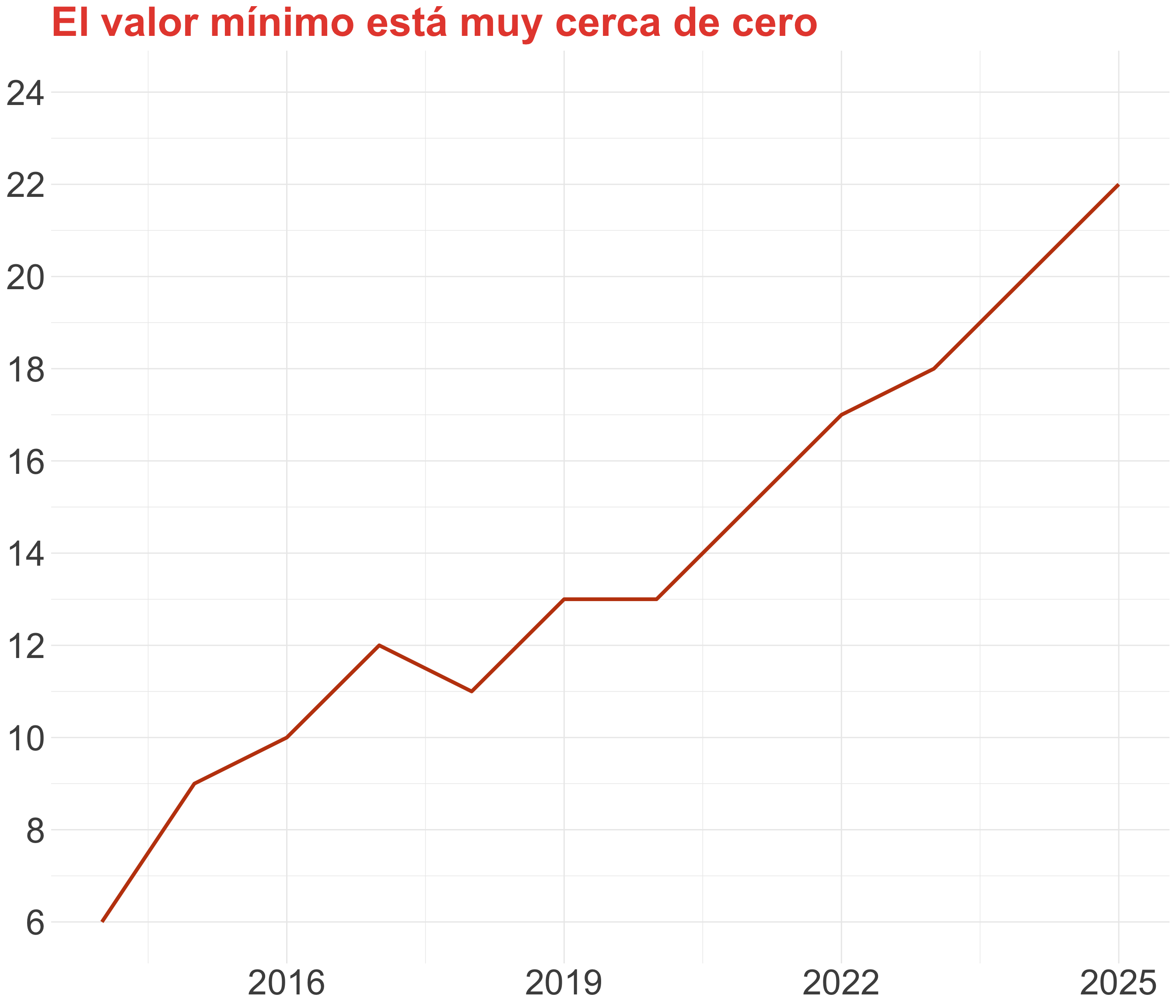
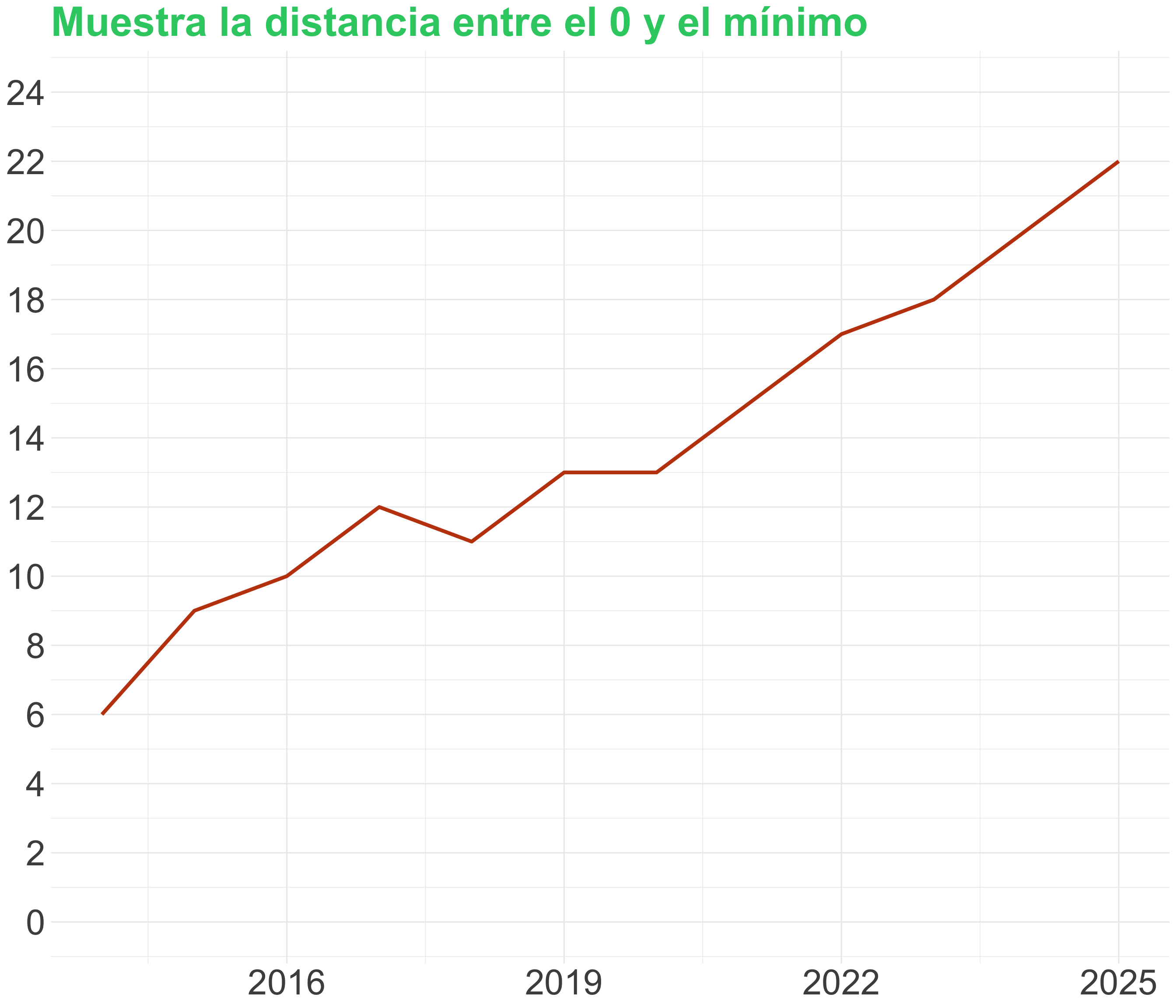
¡Cuidado al truncar el eje! (II)
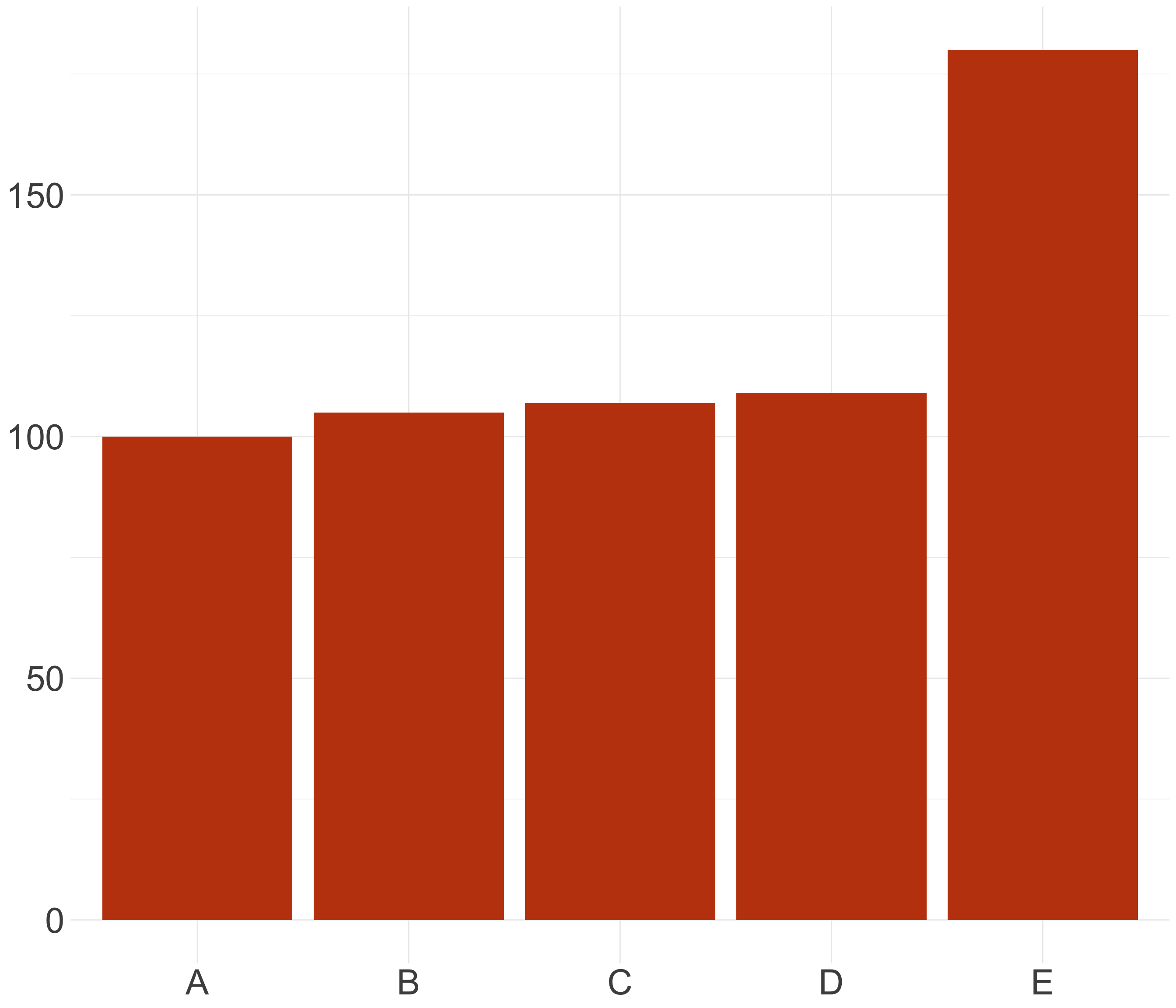
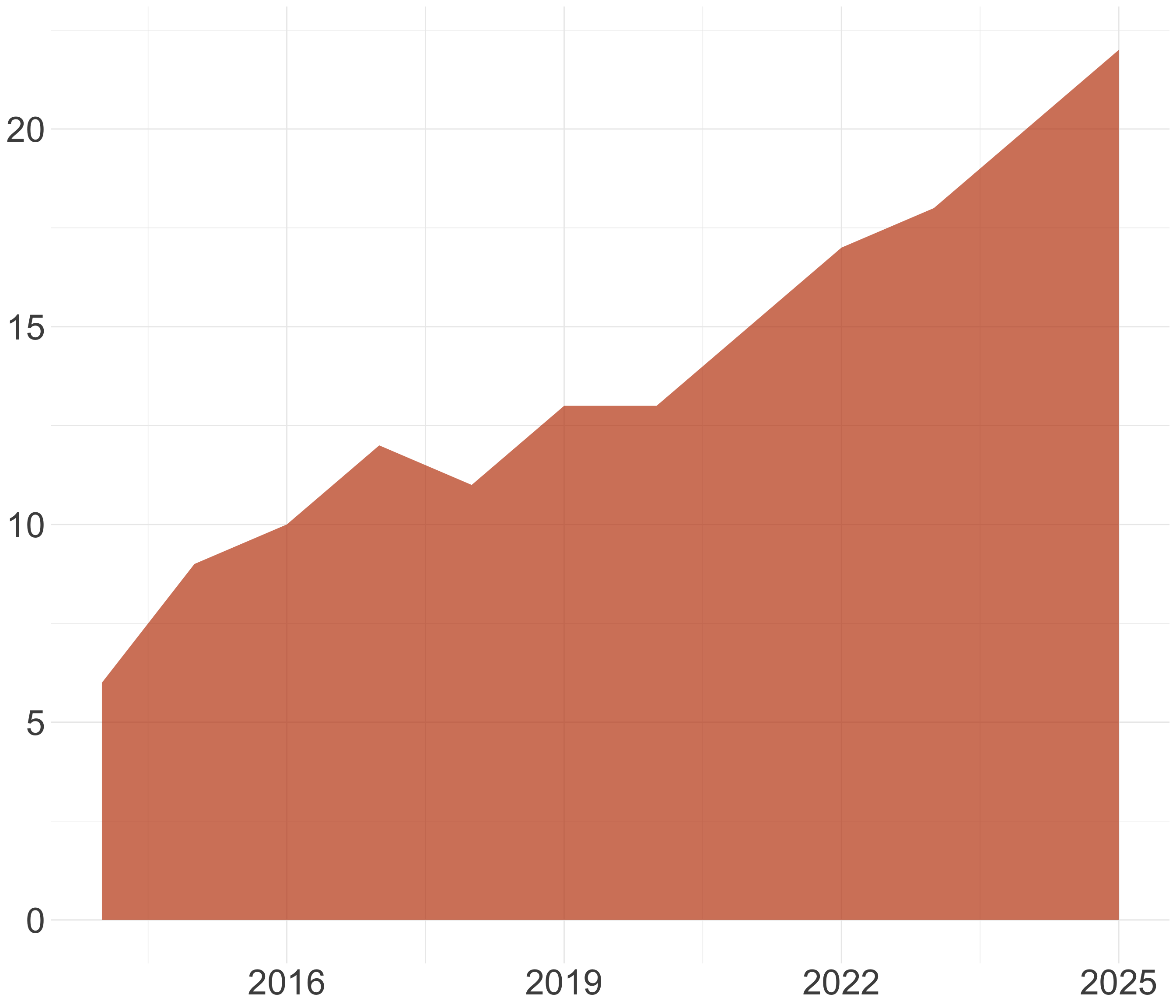
¡Cuidado al truncar el eje! (III)
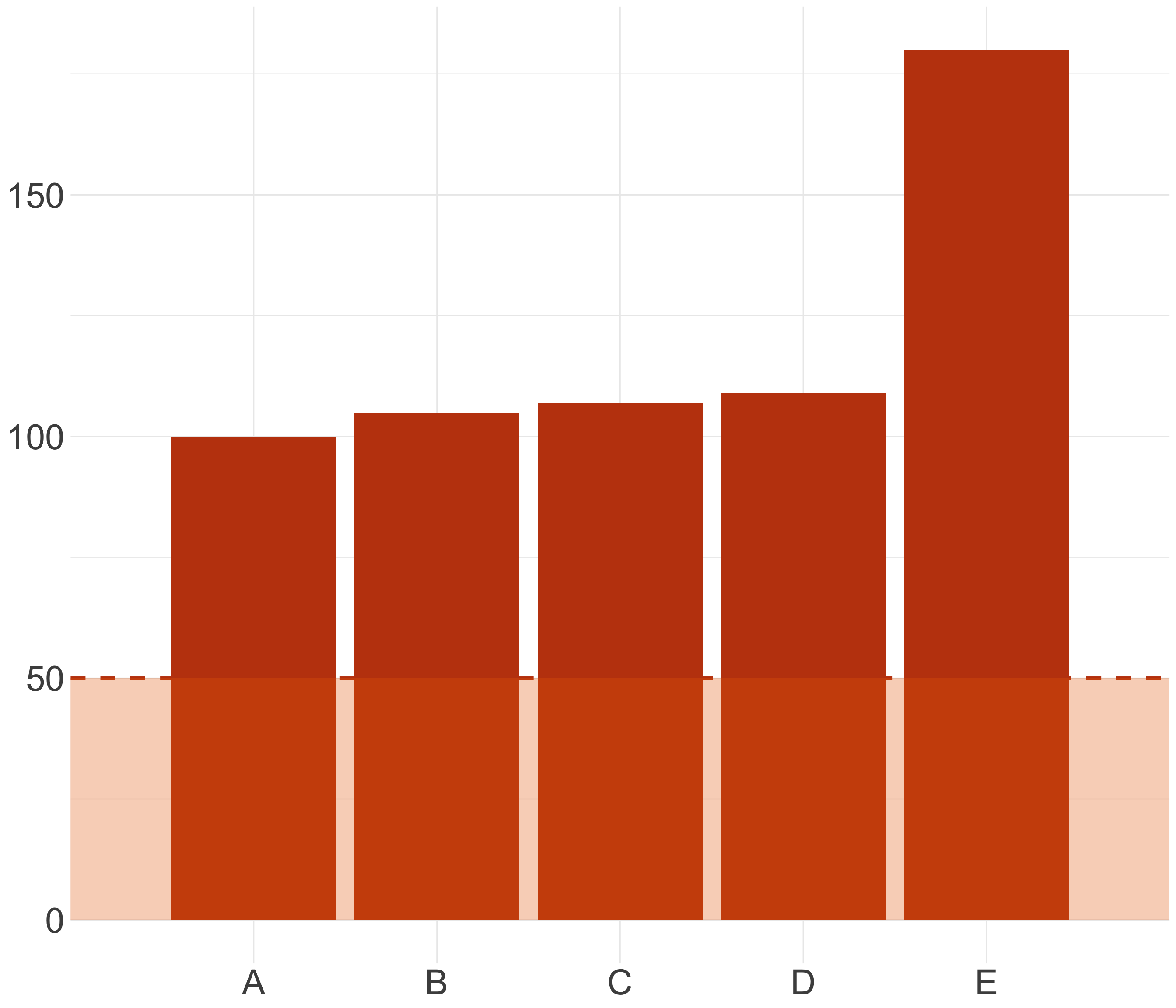
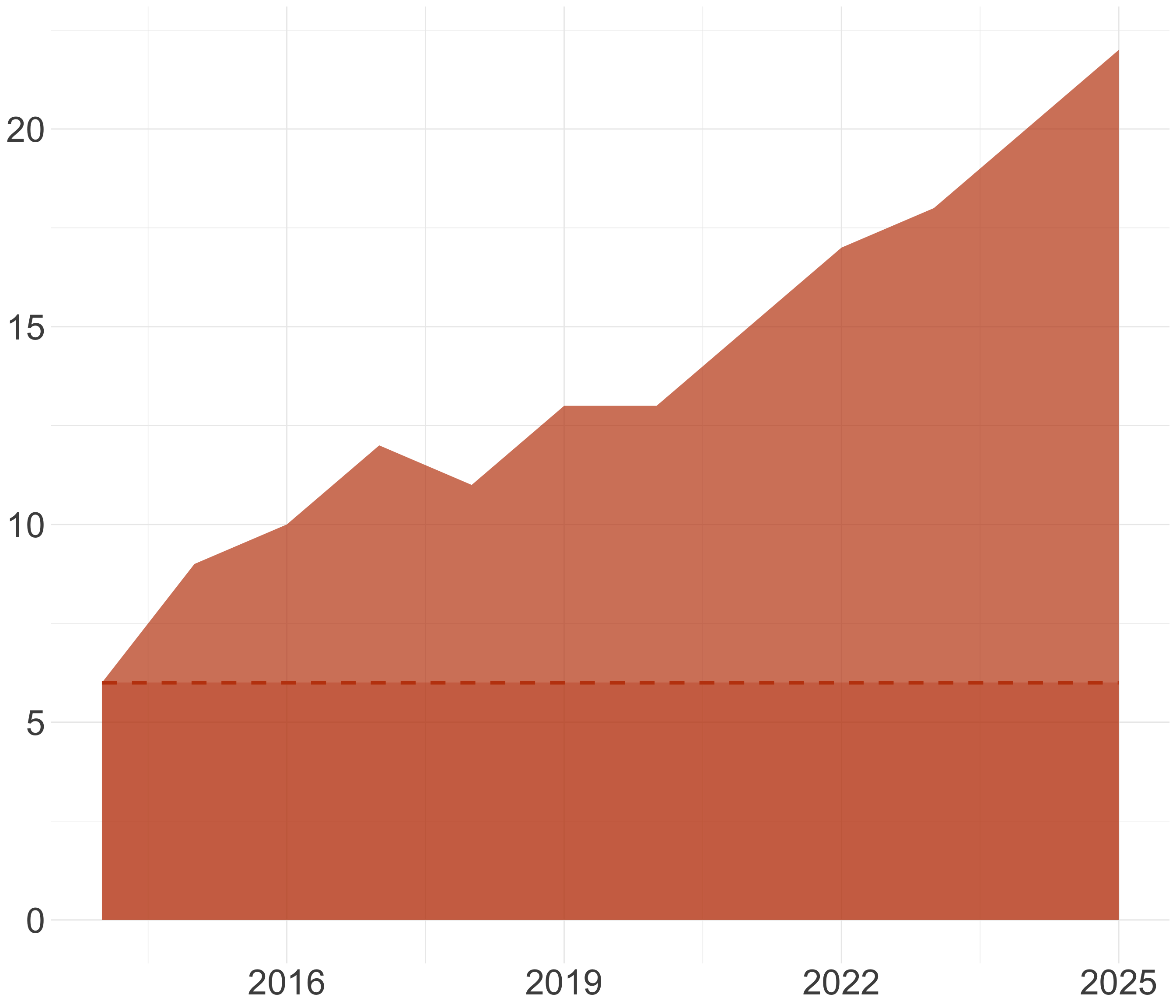
Warning
Los gráficos que muestran o comparan volúmenes entre sí siempre deben comenzar en cero
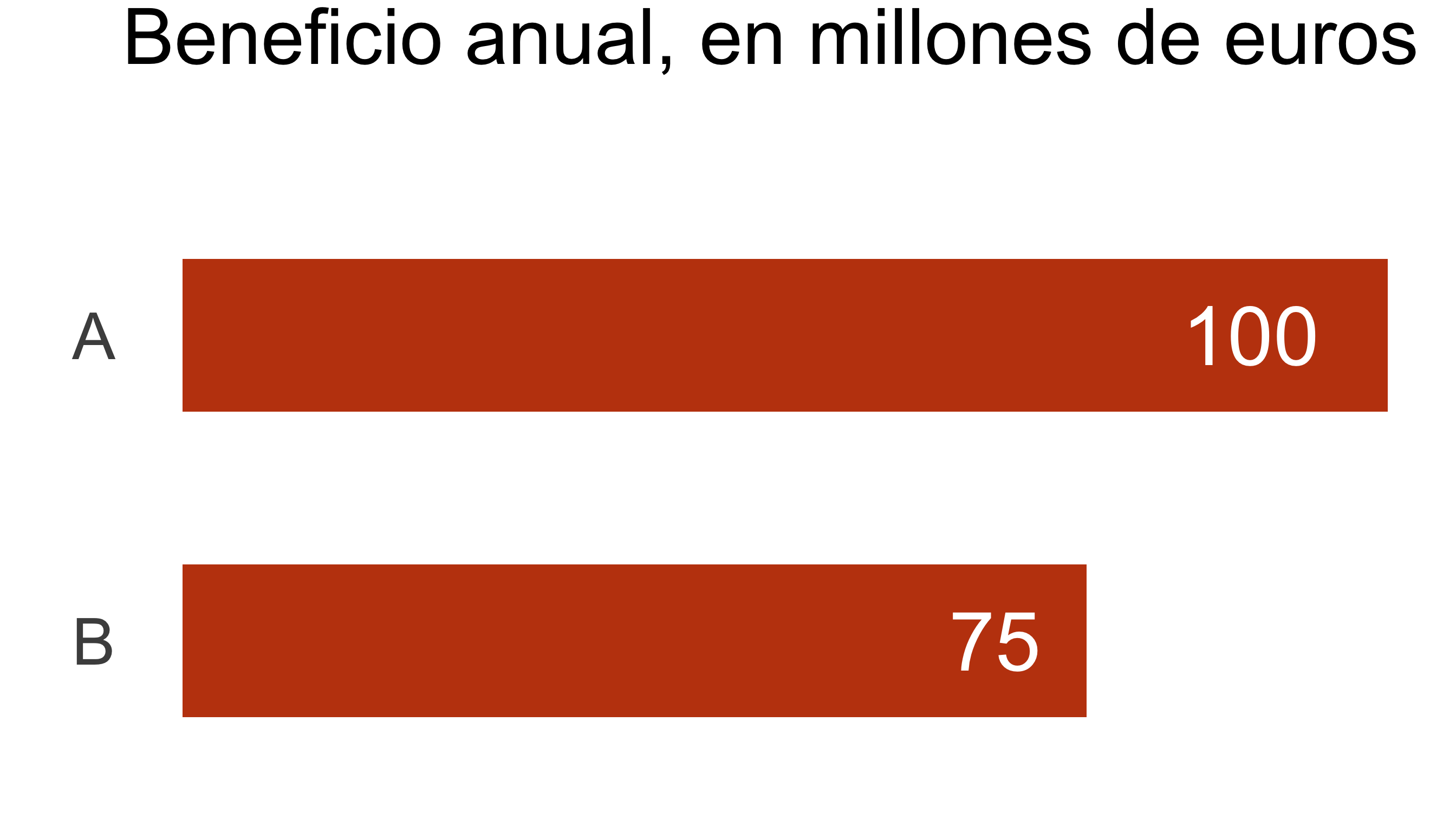
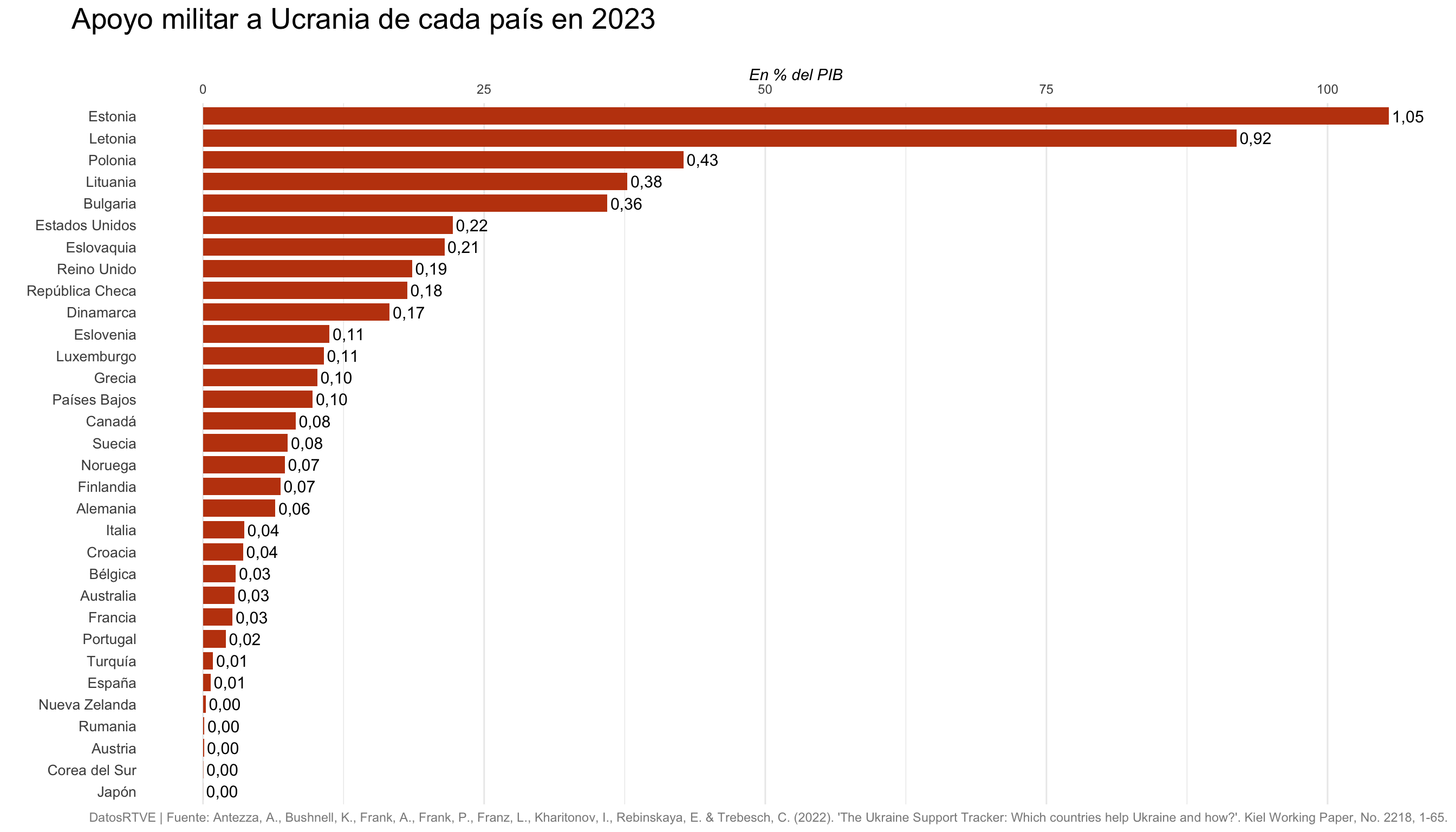
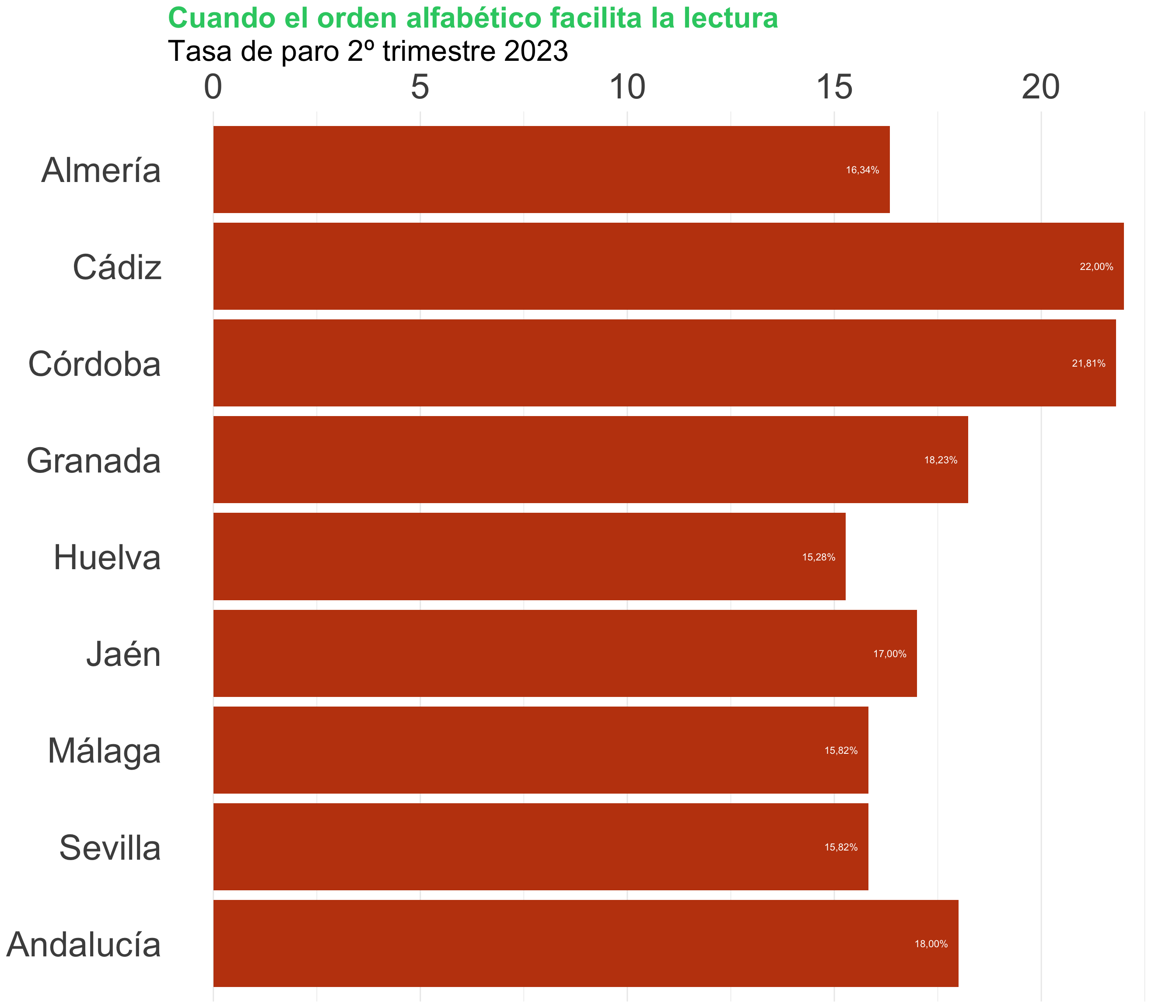
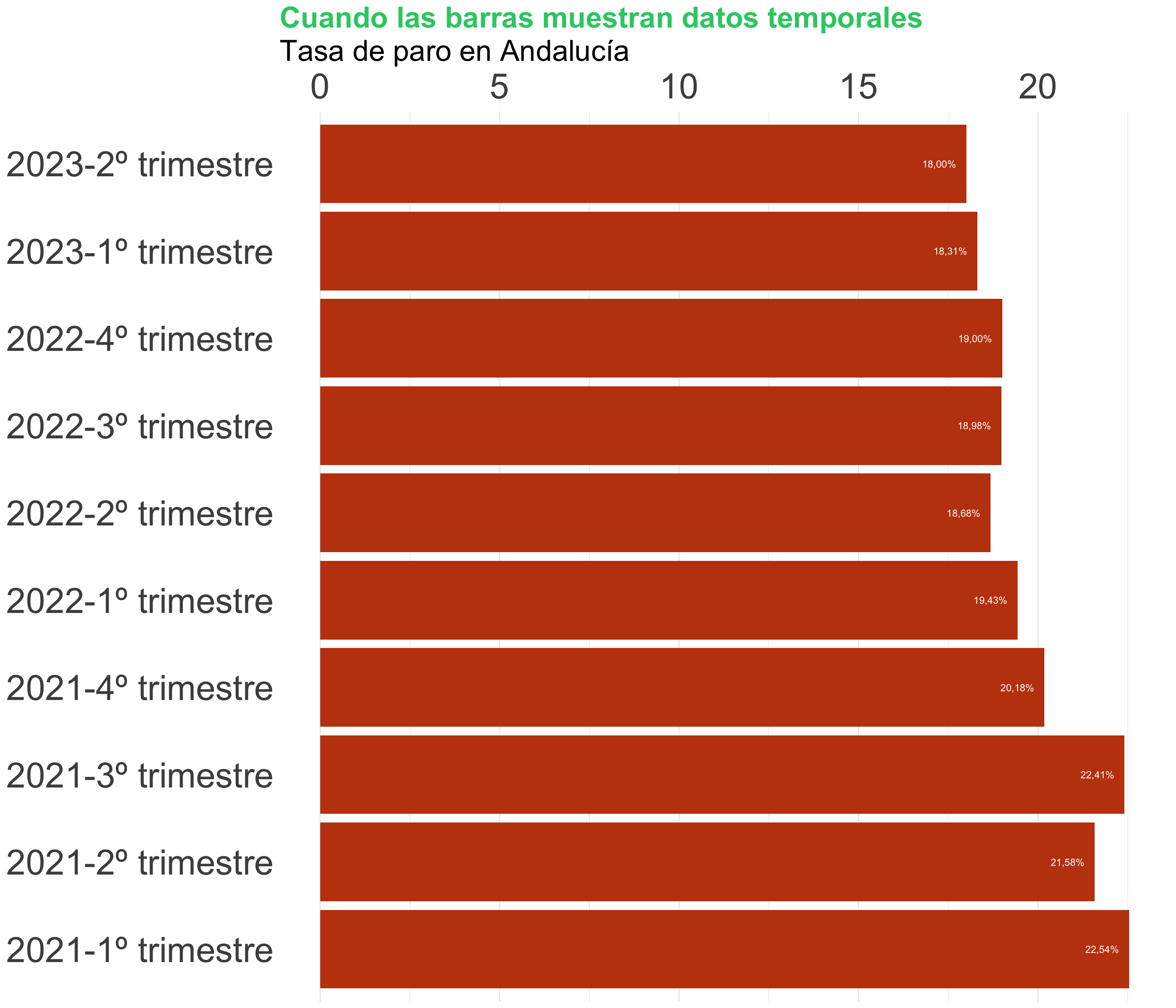
Ordena y reagrupa (I)
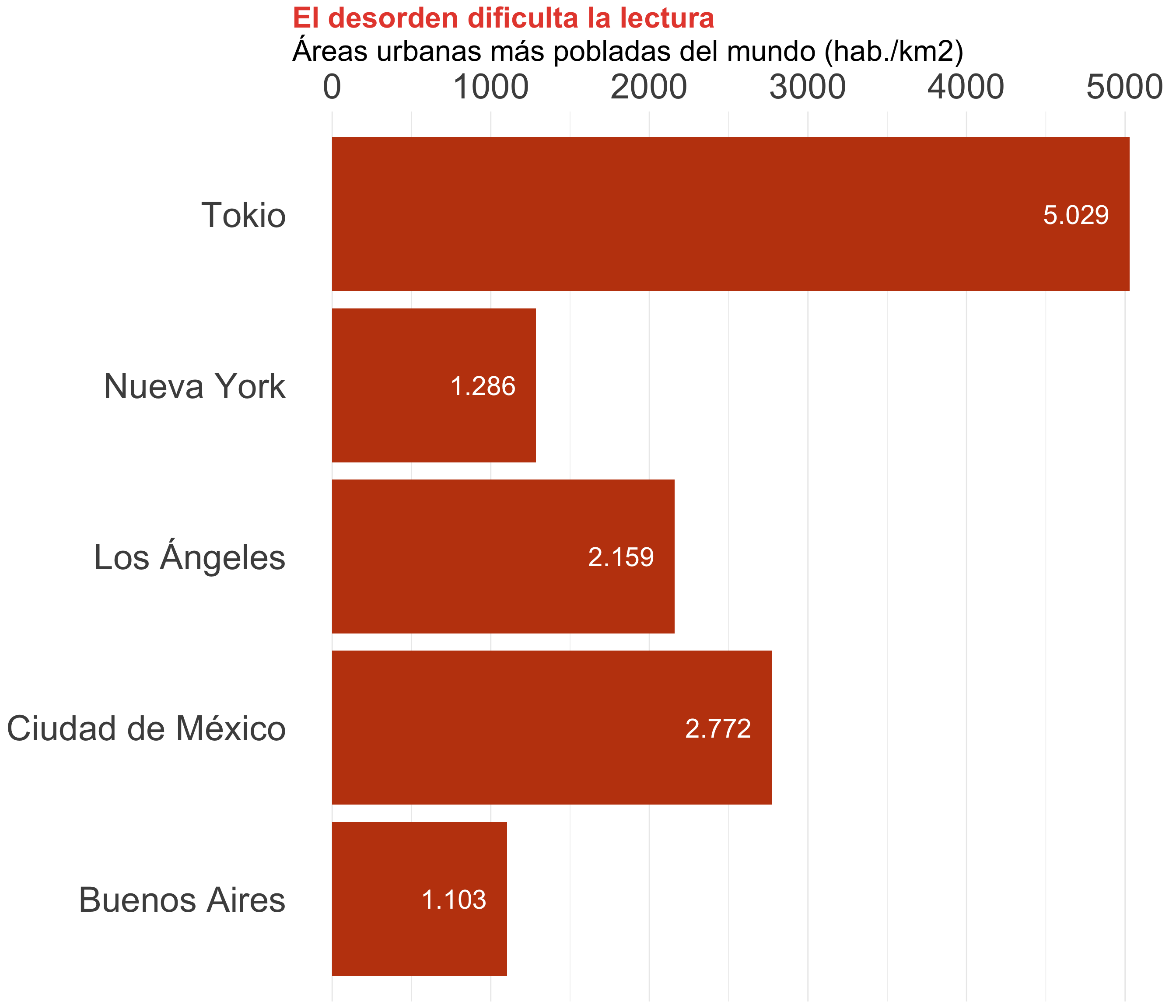
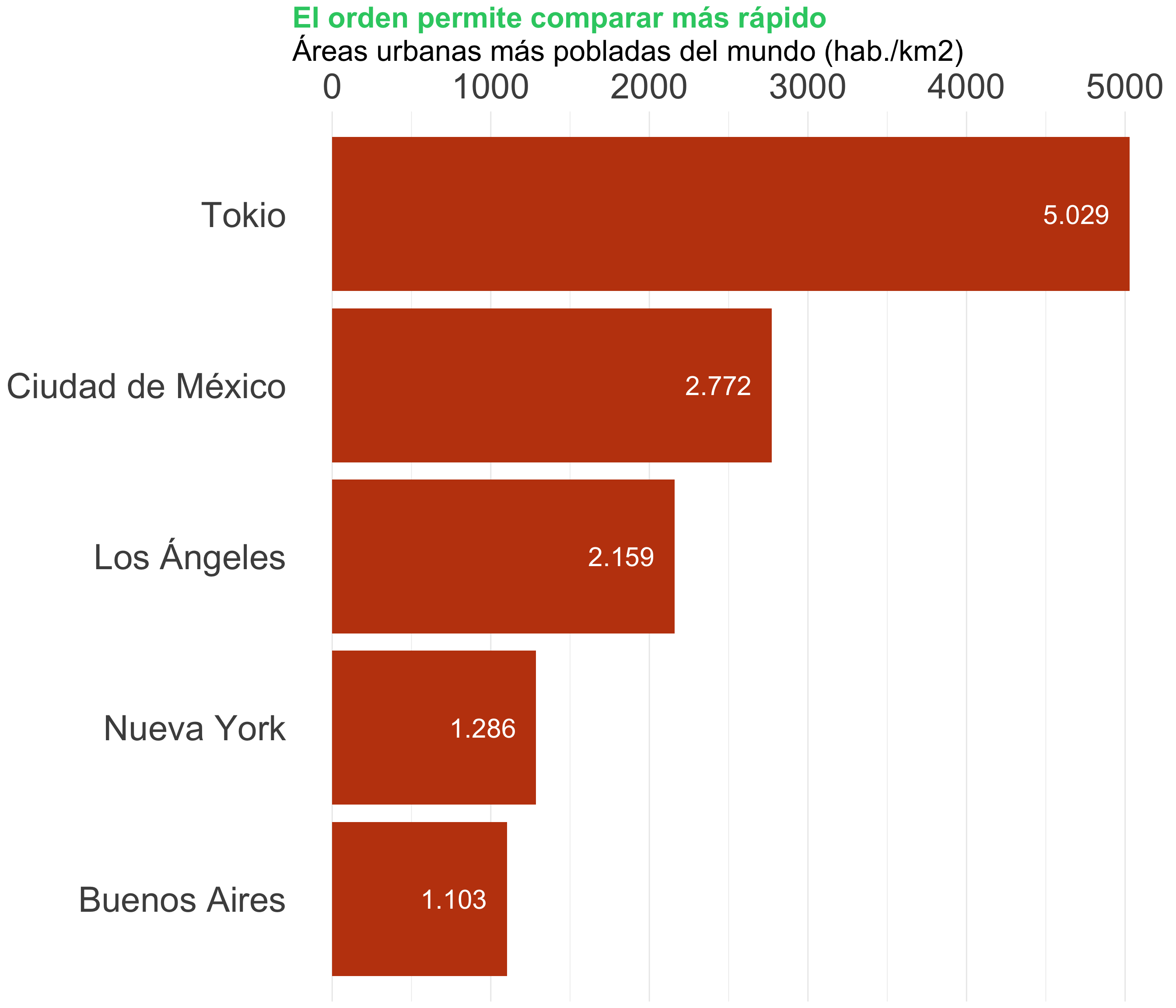
La cualidad principal de un gráfico de barras es que crea un ranking
Ordenar las barras de mayor a menor (o viceversa) facilita la lectura
También puedes destacar una de las barras para reforzar el relato
Ordena y reagrupa (II)
Hay algunas excepciones:
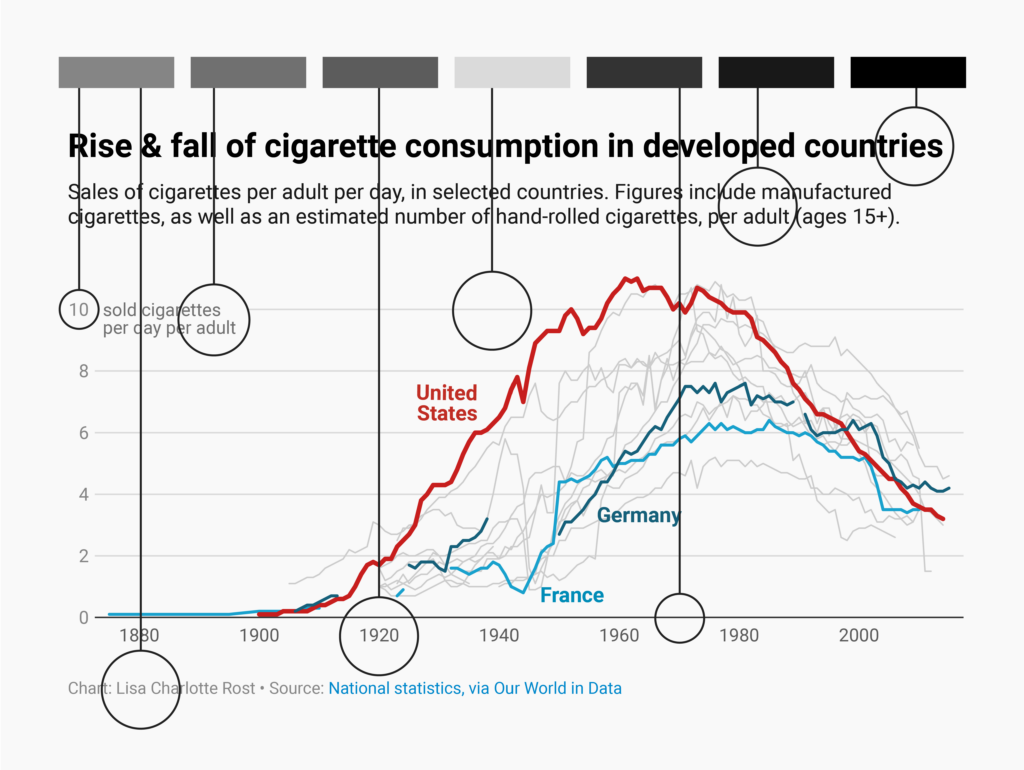
Leyendas y anotaciones (I)
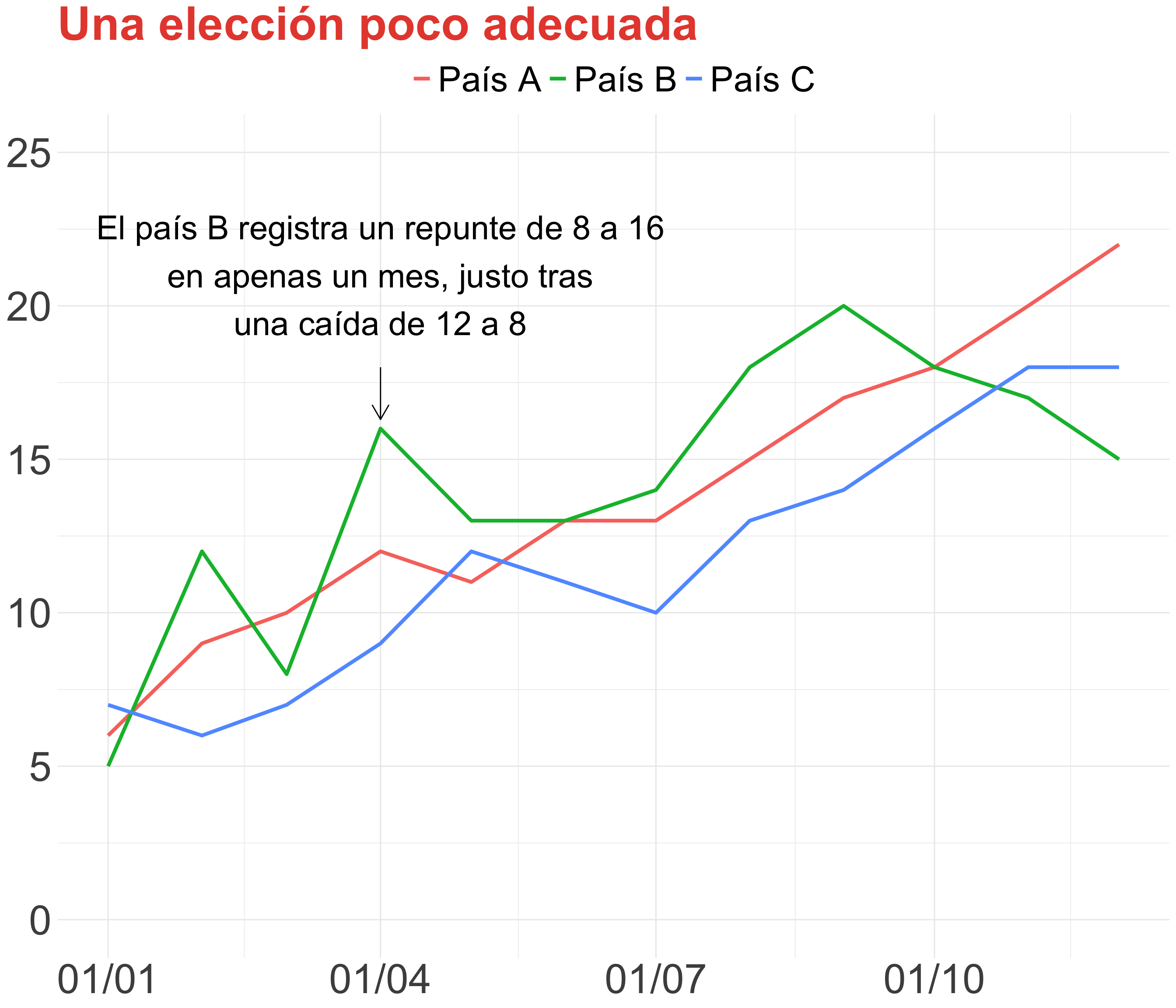
Una leyenda separada de las líneas obliga a trabajar más al espectador
Nunca incluyas anotaciones largas y utiliza solo las necesarias
Leyendas y anotaciones (II)
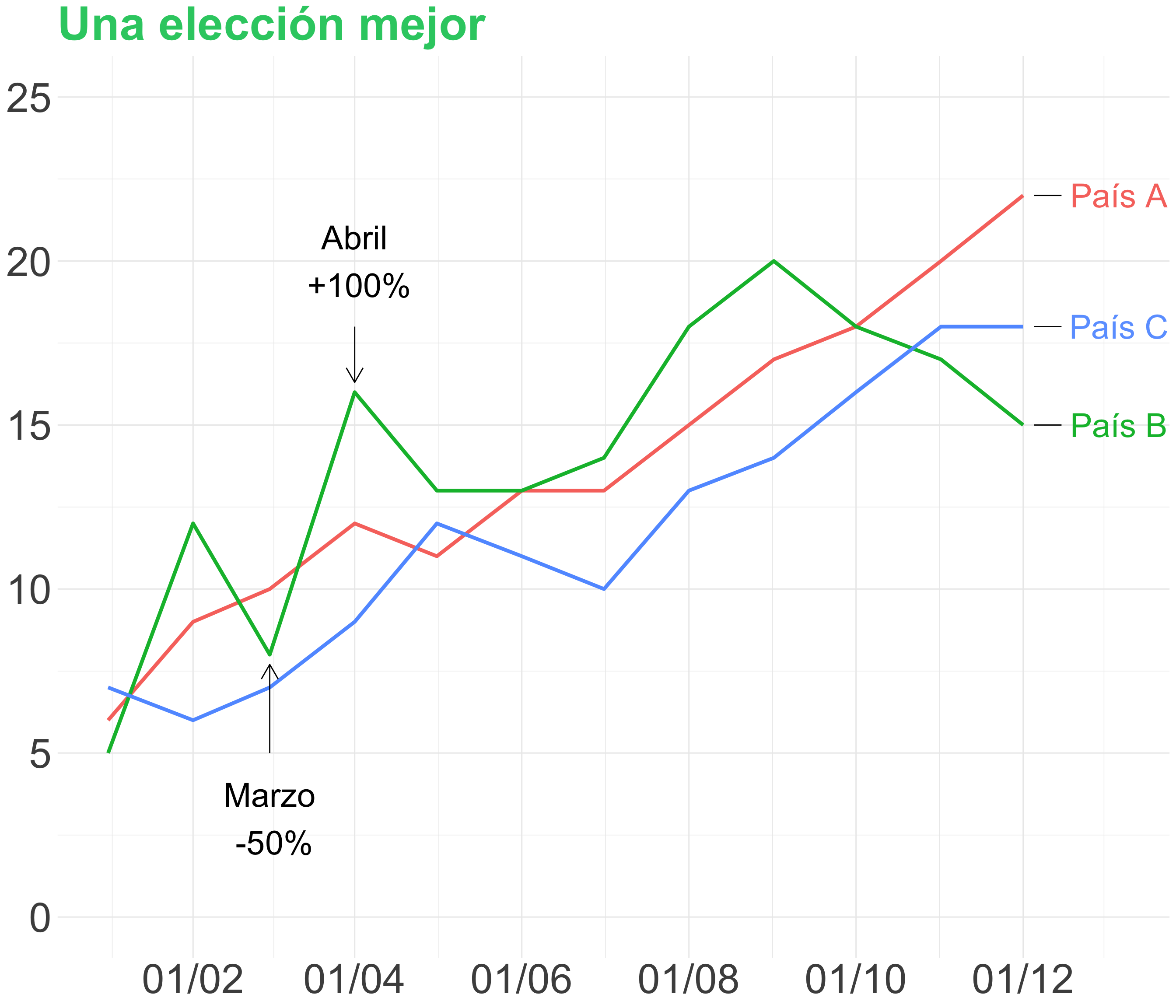
Las etiquetas junto a las líneas permiten una identificación rápida y directa
Las anotaciones han de ser claras y concisas
Defensa contra los gráficos deshonestos

Los gráficos son una ventana al mundo. Cuando están bien hechos, nos enseñan a entender quiénes somos, dónde estamos y cómo podemos convertirnos en una versión mejor de nosotros mismos. Sin embargo, cuando están mal hechos, en ausencia de verdad, los gráficos pueden ser dañinos. Nathan Yau, Flowingdata
¿Qué historia quieres contar?
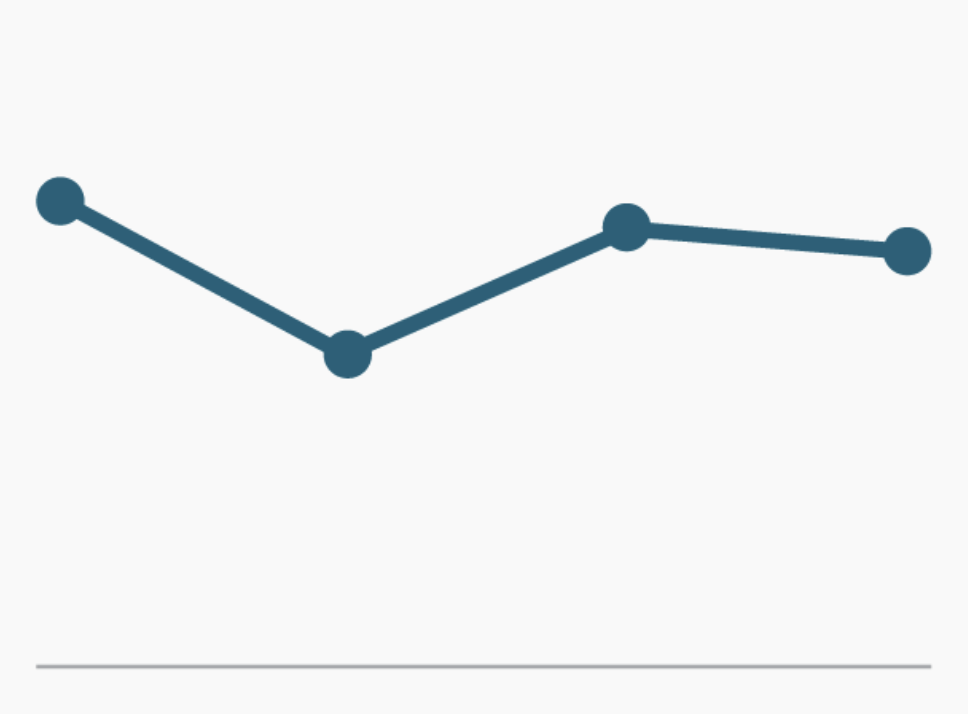 |
 |
 |
| Gráfico de línea | Gráfico de áreas | Gráfico de líneas múltiple |
| Si solo tienes una variable | Si tienes más de una variable y forman parte de un todo | Si tienes múltiples variables que no forman un todo pero comparten una unidad de medida |
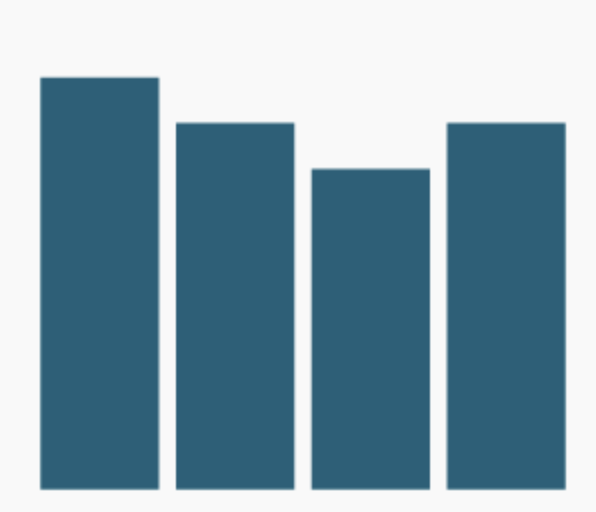 |
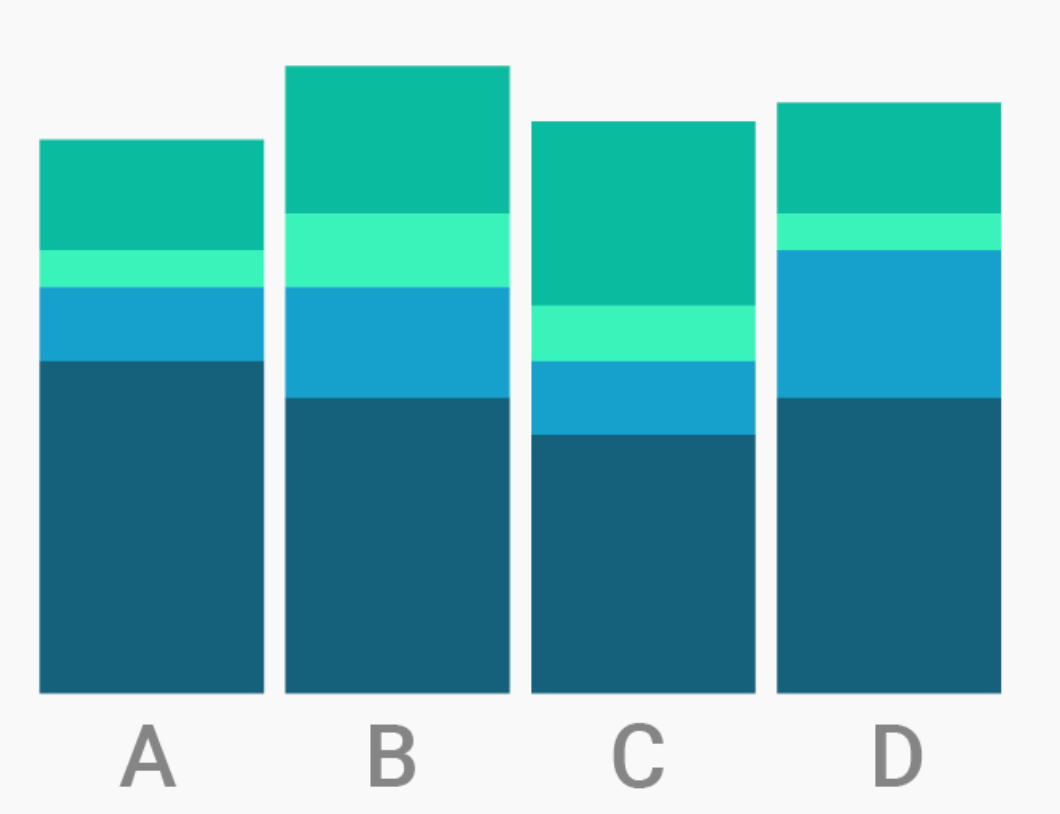 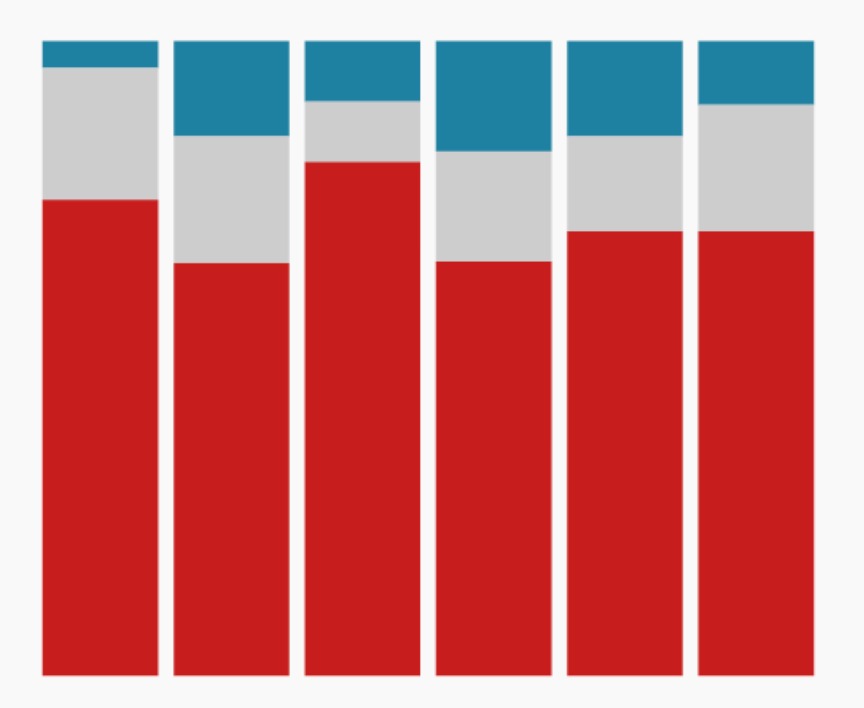 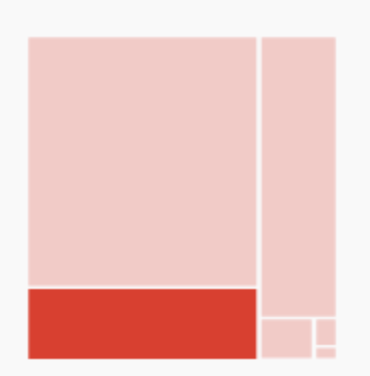 |
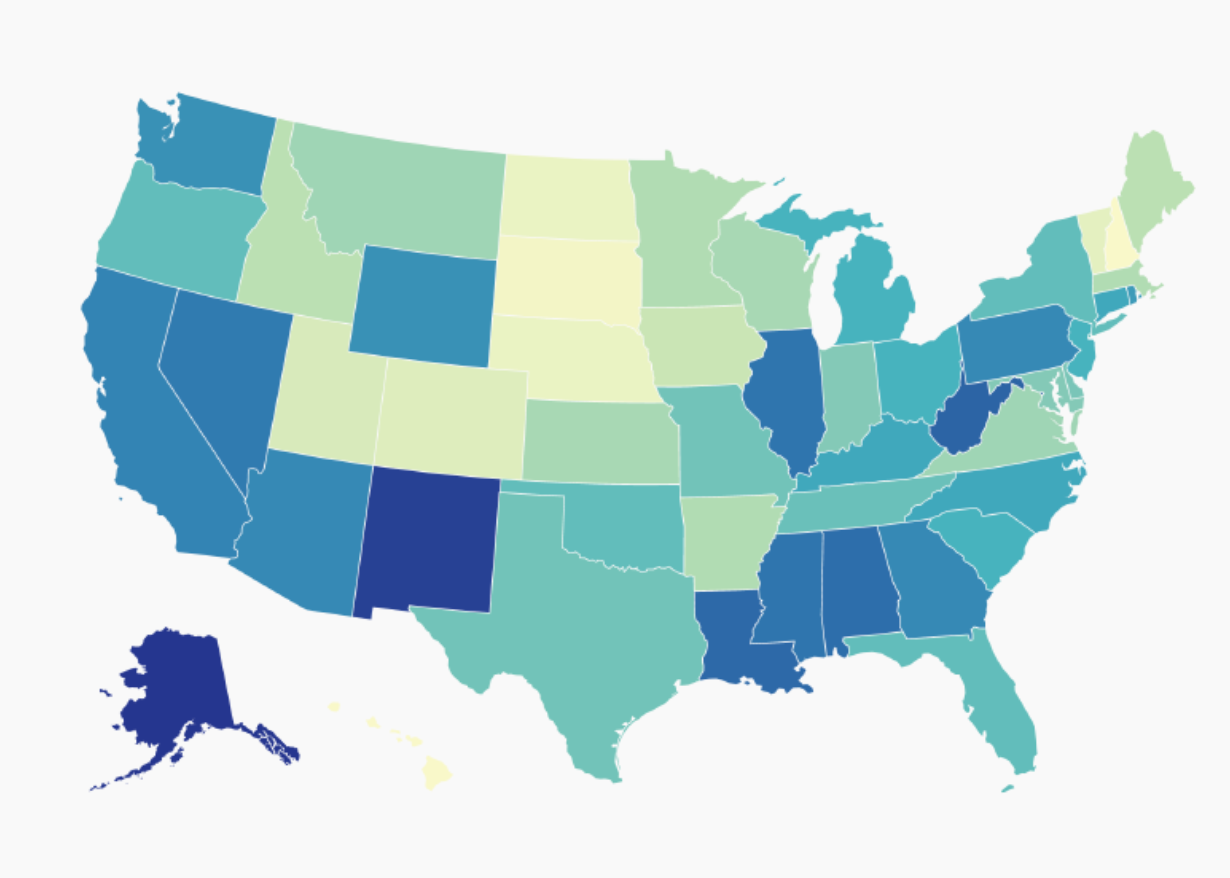 |
| Gráfico de columnas | Columnas apiladas / stacked / treemap | Mapas de coropletas |
| Magnitud en el tiempo | Un todo y sus partes | Considerando la geografía |
 |
 |
| Diagrama de dispersión | Histograma |
| Mostrar relación entre dos variables | Mostrar la distribución de una sola variable o de varias |
 |
 |
| Diagrama de Sankey | Diagrama de cuerdas |
| Muestra los flujos de un sistema | Muestra relaciones ponderadas y flujos entre nodos |
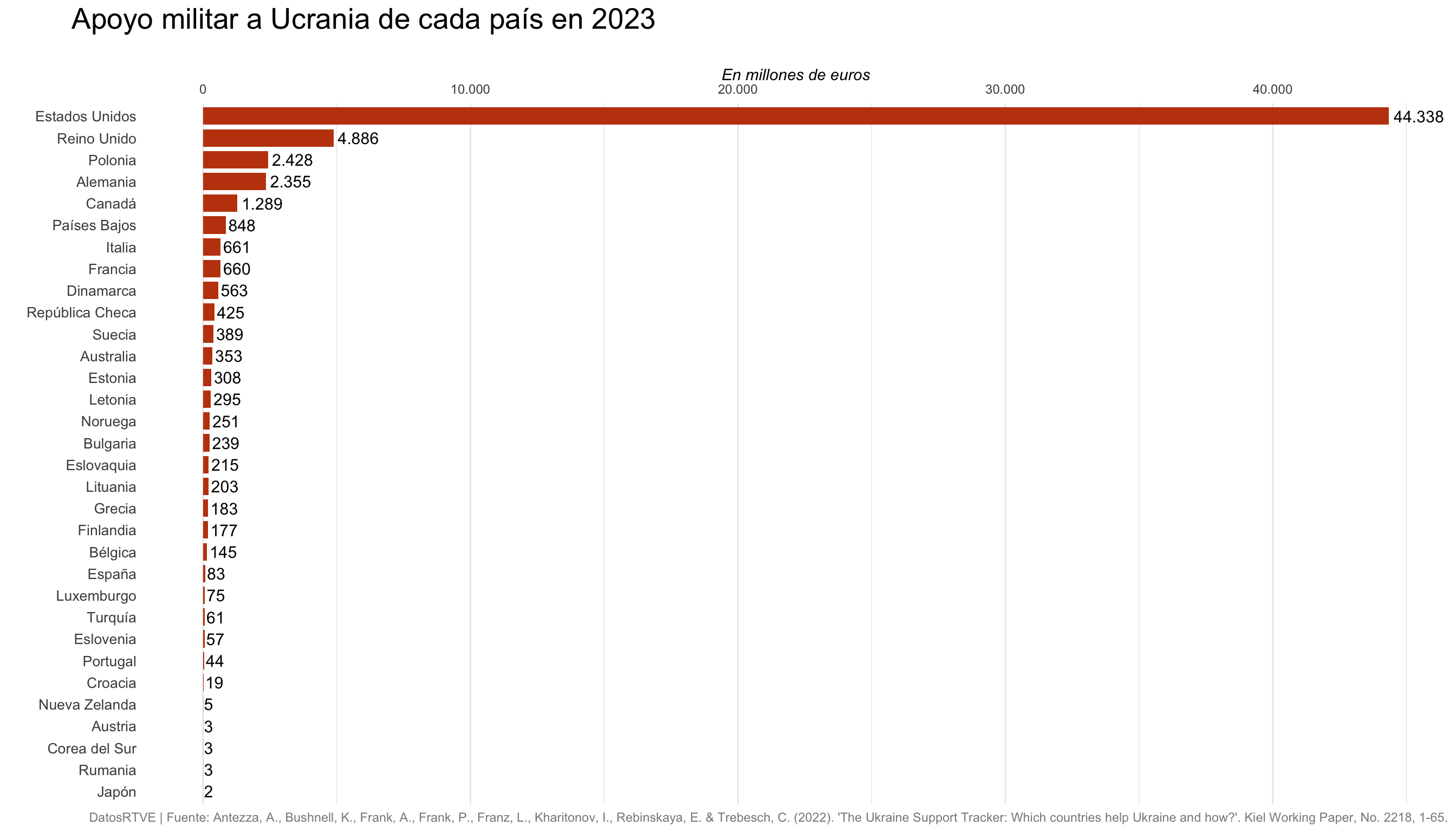
Columnas/barras
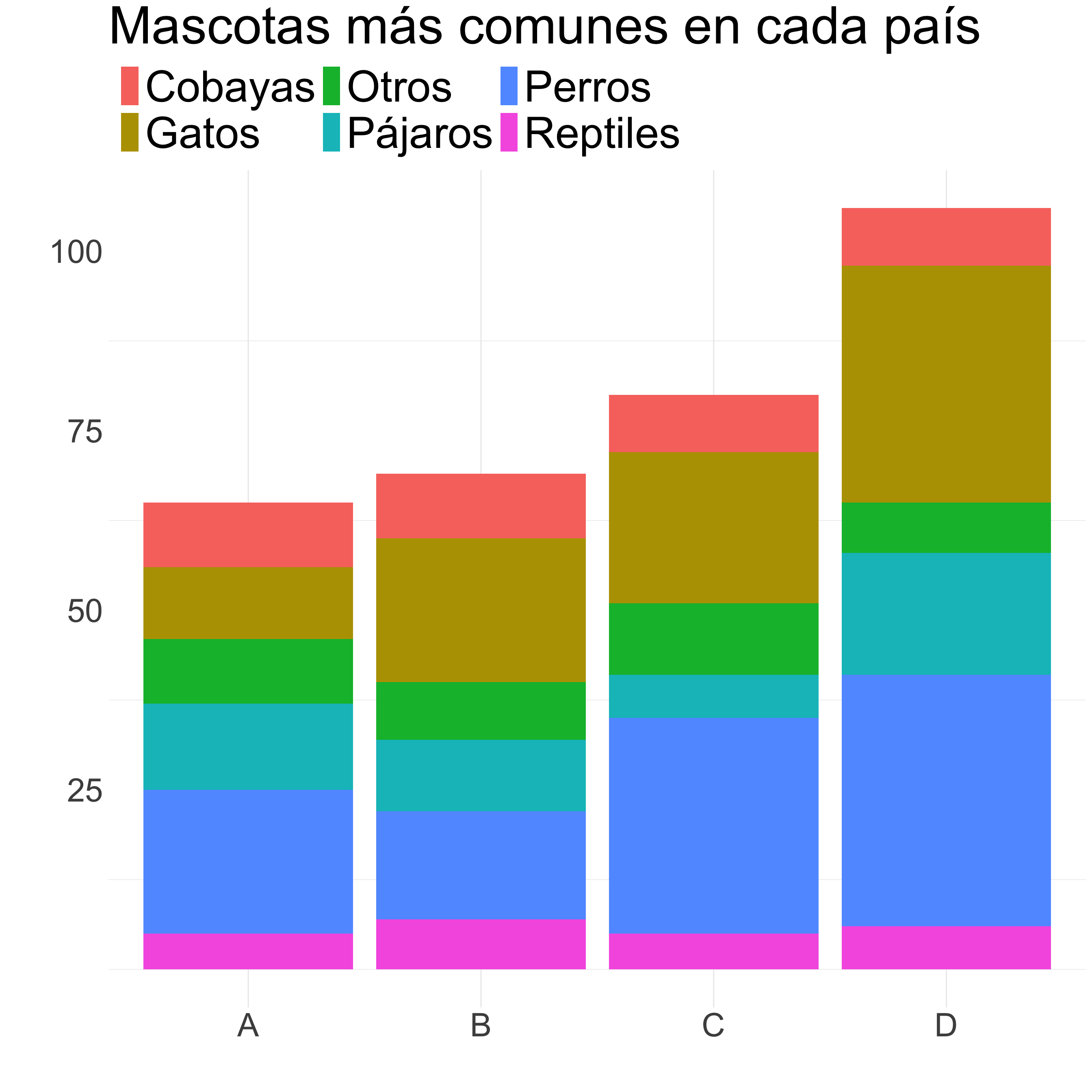
¿Cómo mejoramos este gráfico?
Columnas/barras
¿Cómo mejoramos este gráfico?
- Ordenamos de mayor a menor, con el grupo más numeroso pegado al eje.
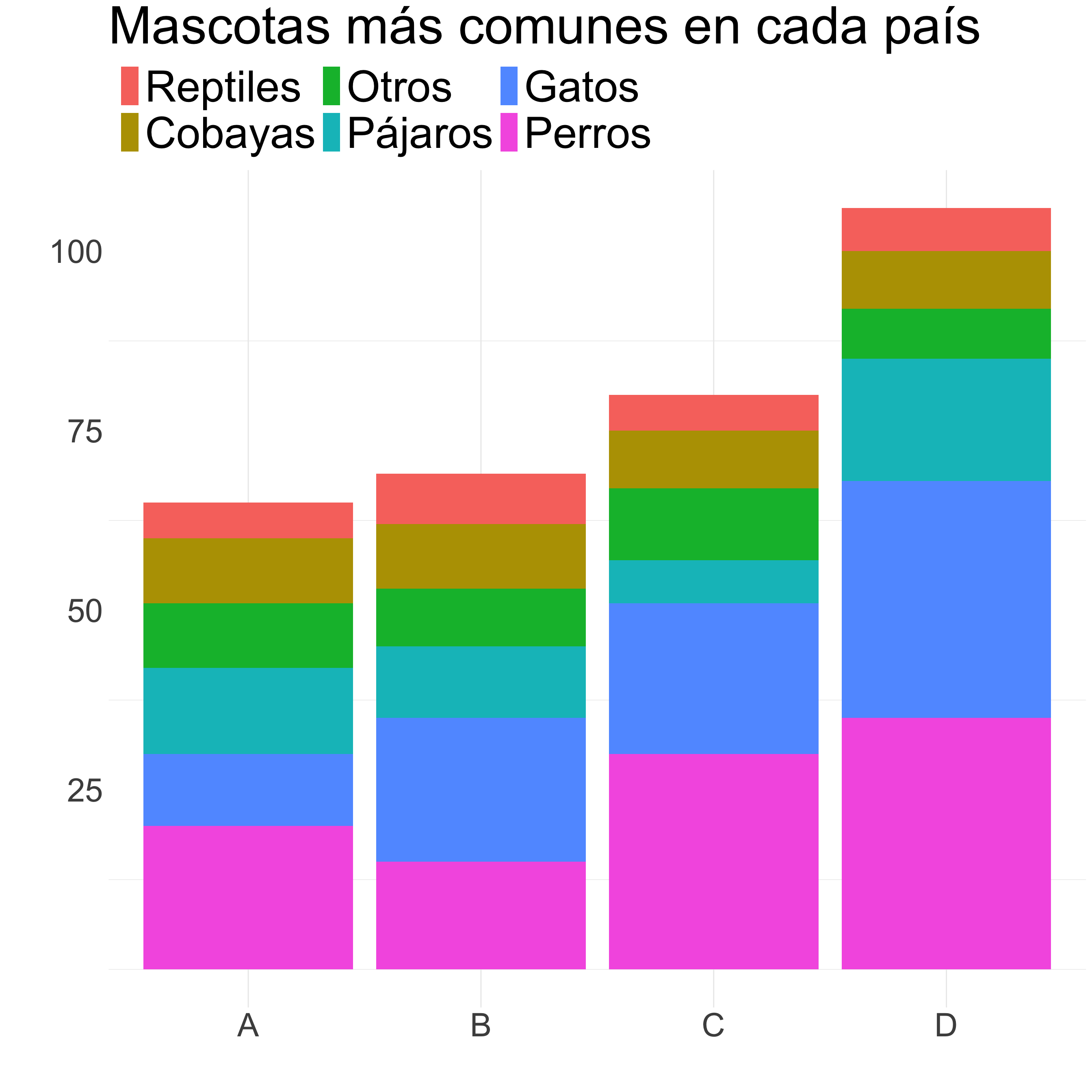
Columnas/barras
¿Cómo mejoramos este gráfico?
Ordenamos de mayor a menor, con el grupo más numeroso pegado al eje.
Agrupo las categorías menos importantes en “Otros”.
Columnas/barras
¿Cómo mejoramos este gráfico?
Ordenamos de mayor a menor, con el grupo más numeroso pegado al eje.
Agrupo las categorías menos importantes en “Otros”.
Aplicamos una paleta de colores más limpia.
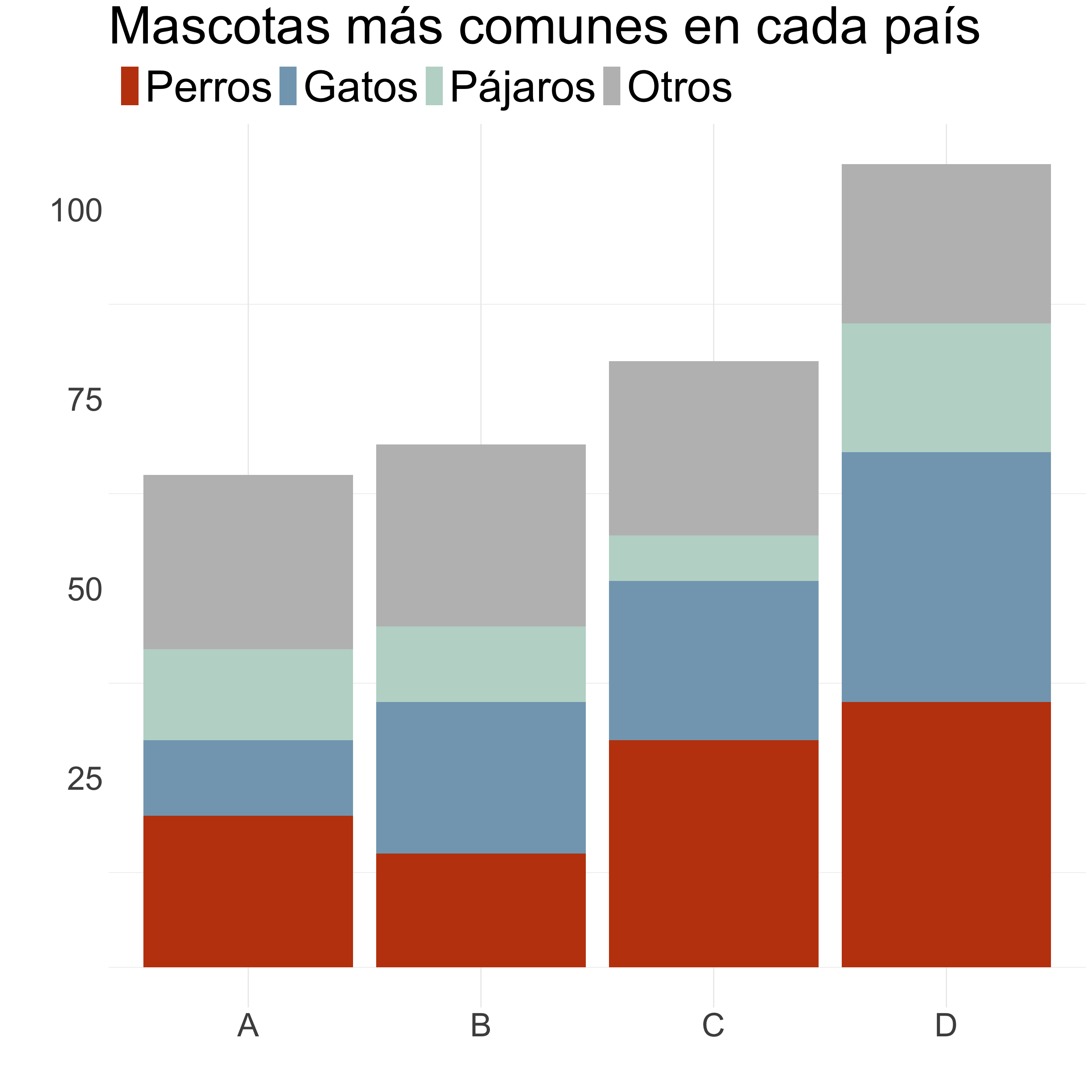
Columnas/barras
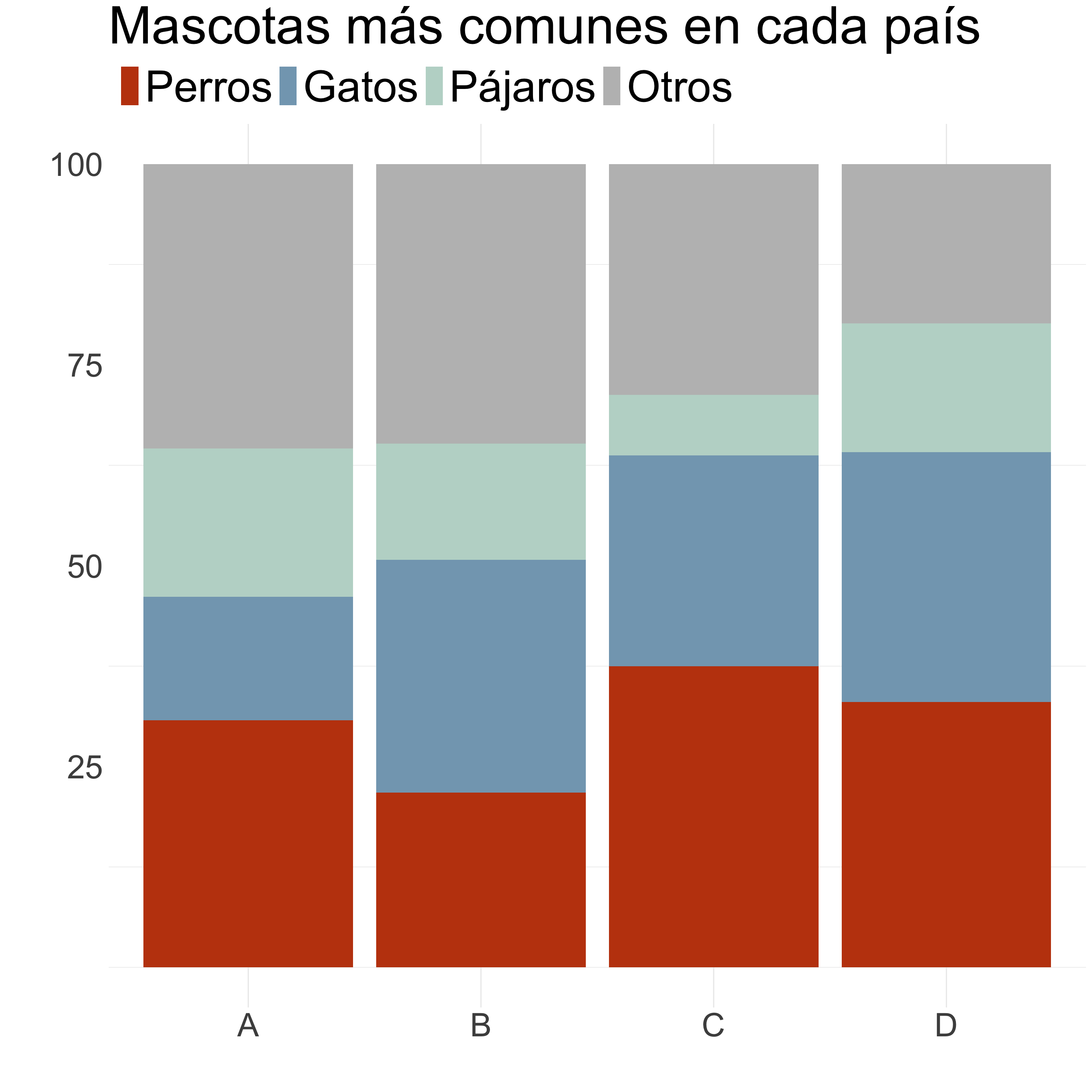
¿Cómo mejoramos este gráfico?
Ordenamos de mayor a menor, con el grupo más numeroso pegado al eje.
Agrupo las categorías menos importantes en “Otros”.
Aplicamos una paleta de colores más limpia.
Calculamos porcentajes para poder comparar.
Columnas/barras
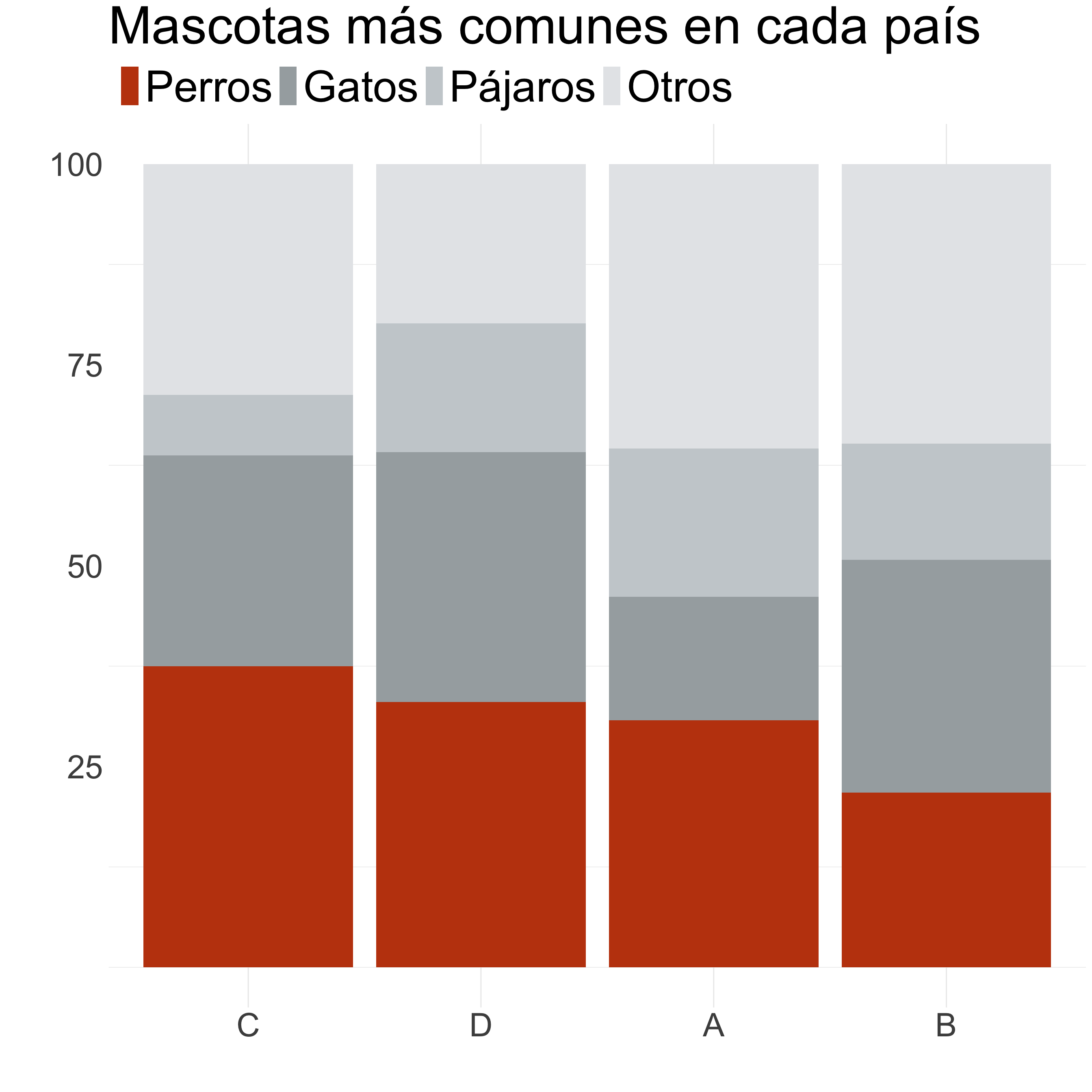
¿Cómo mejoramos este gráfico?
Ordenamos de mayor a menor, con el grupo más numeroso pegado al eje.
Agrupo las categorías menos importantes en “Otros”.
Aplicamos una paleta de colores más limpia.
Calculamos porcentajes para poder comparar.
Destacamos una variable y reordenamos.
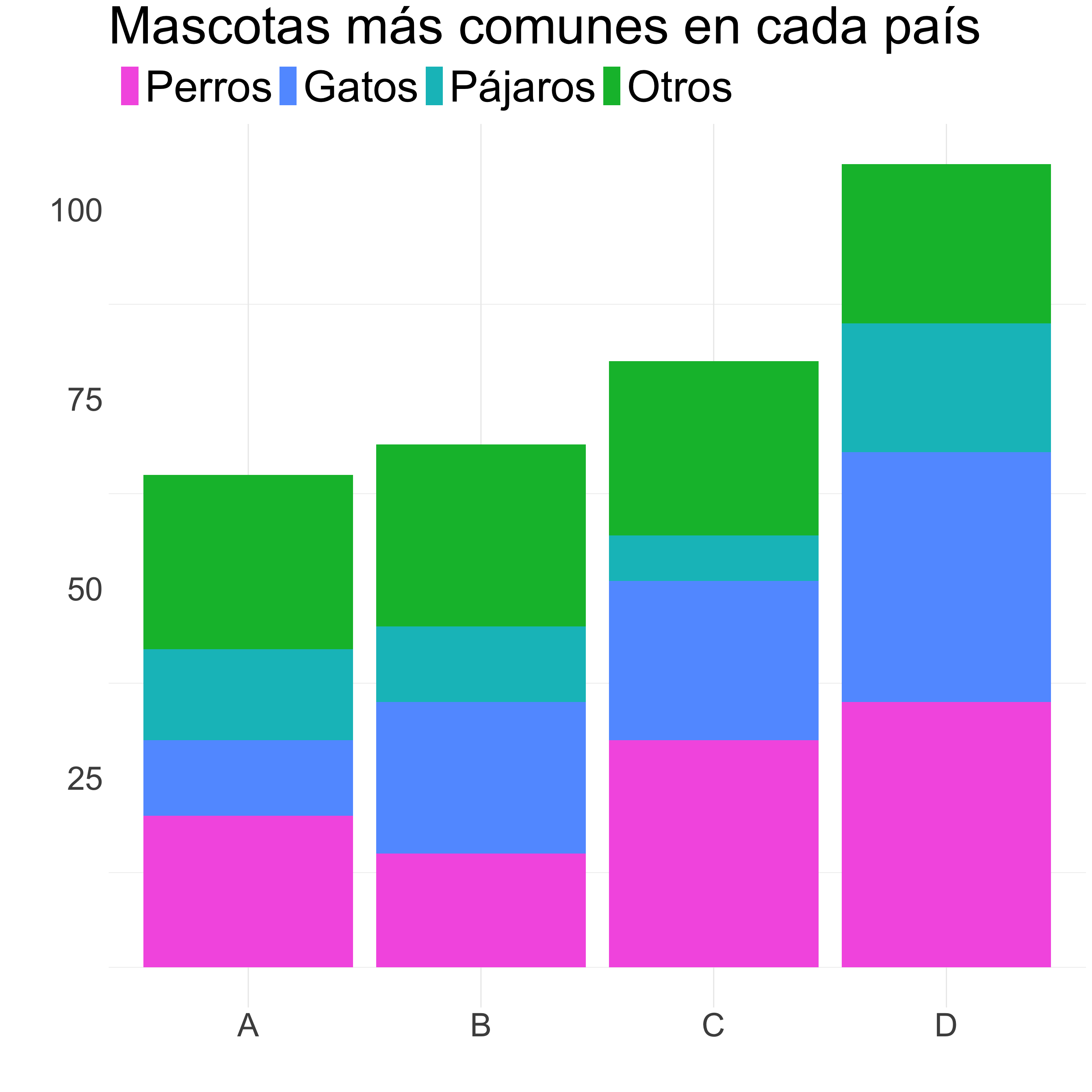
Columnas/barras
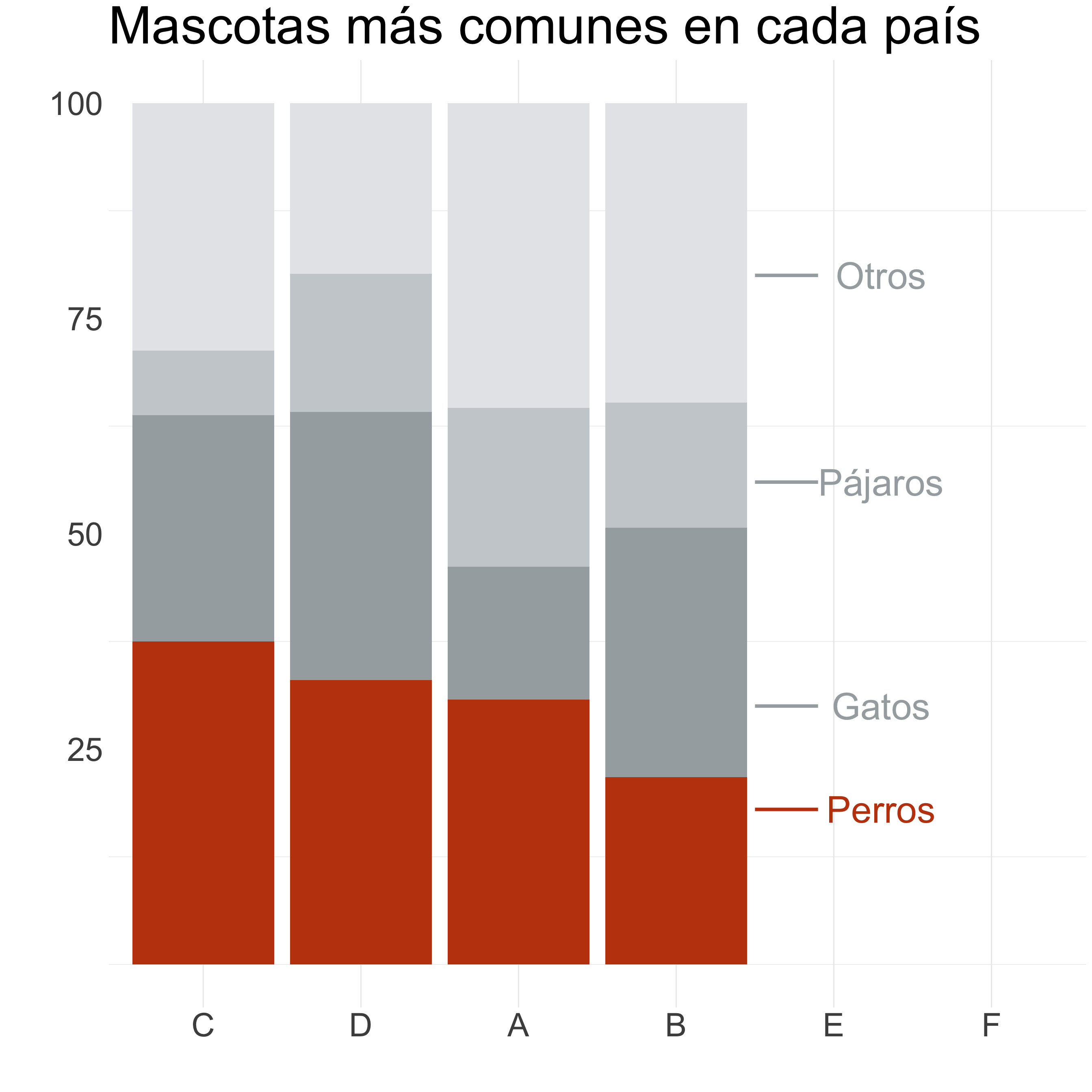
¿Cómo mejoramos este gráfico?
Ordenamos de mayor a menor, con el grupo más numeroso pegado al eje.
Agrupo las categorías menos importantes en “Otros”.
Aplicamos una paleta de colores más limpia.
Calculamos porcentajes para poder comparar.
Destacamos una variable y reordenamos.
Colocamos la leyenda junto a las barras.
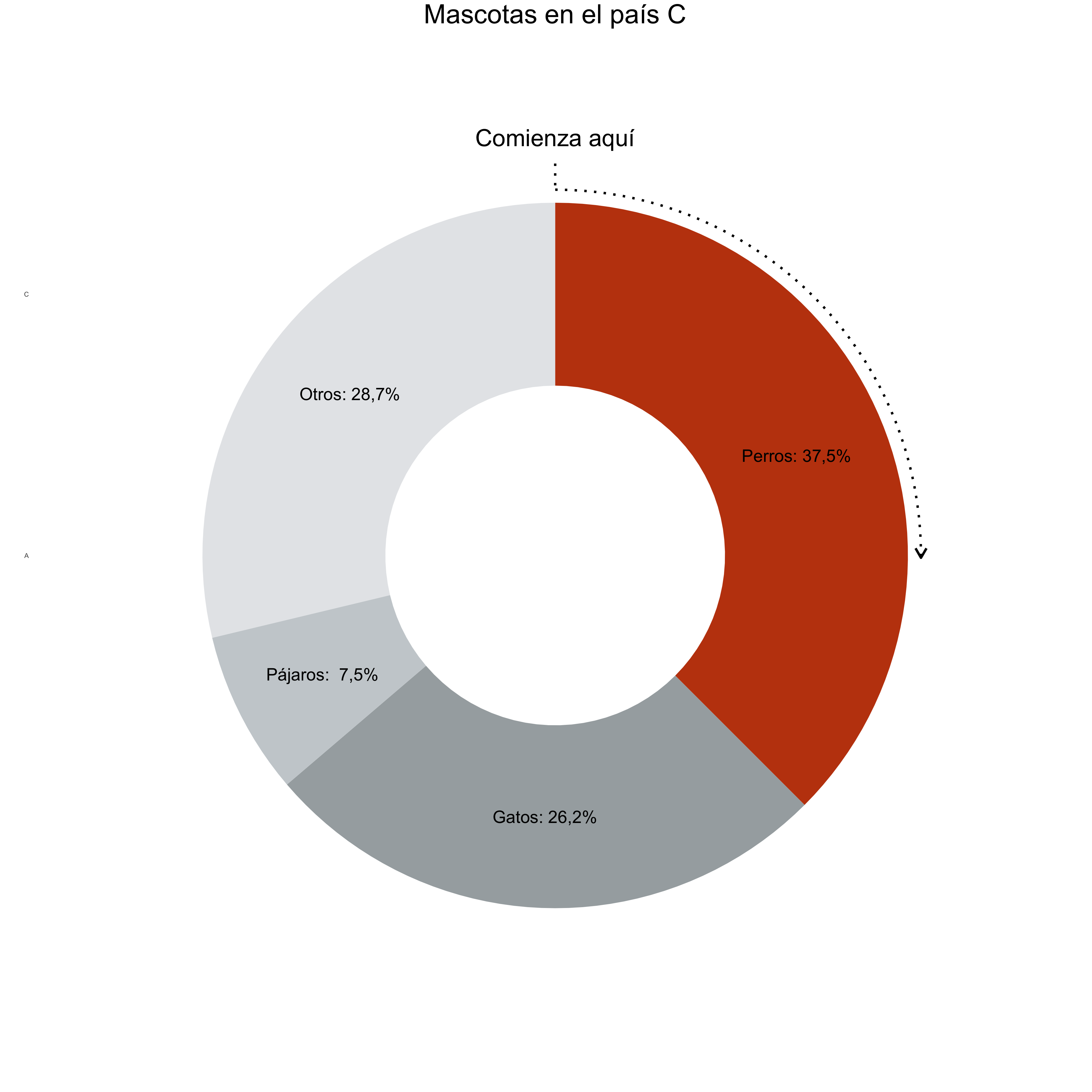
Tarta/donut
Sirven para mostrar las partes de un todo (100%)
Funcionan mejor con datos alrededor del 25, 50 o 75%, más fáciles de reconocer
Reduce el número de valores agrupando las partes más pequeñas
Destaca el valor más importante y usa un degradado para el resto
Como en las líneas y las barras, coloca etiquetas directas en vez de leyenda
Tip
Si pretendes que el lector compare el tamaño de cada parte, opta mejor por un gráfico de barras. Sobre todo si las diferencias son pequeñas
Tarta/donut
Los gráficos de tarta se leen como un reloj. Coloca los valores de mayor a menor hacia la derecha desde las 12 en punto. Puedes dejar la categoria “Otros” al final.
Treemap
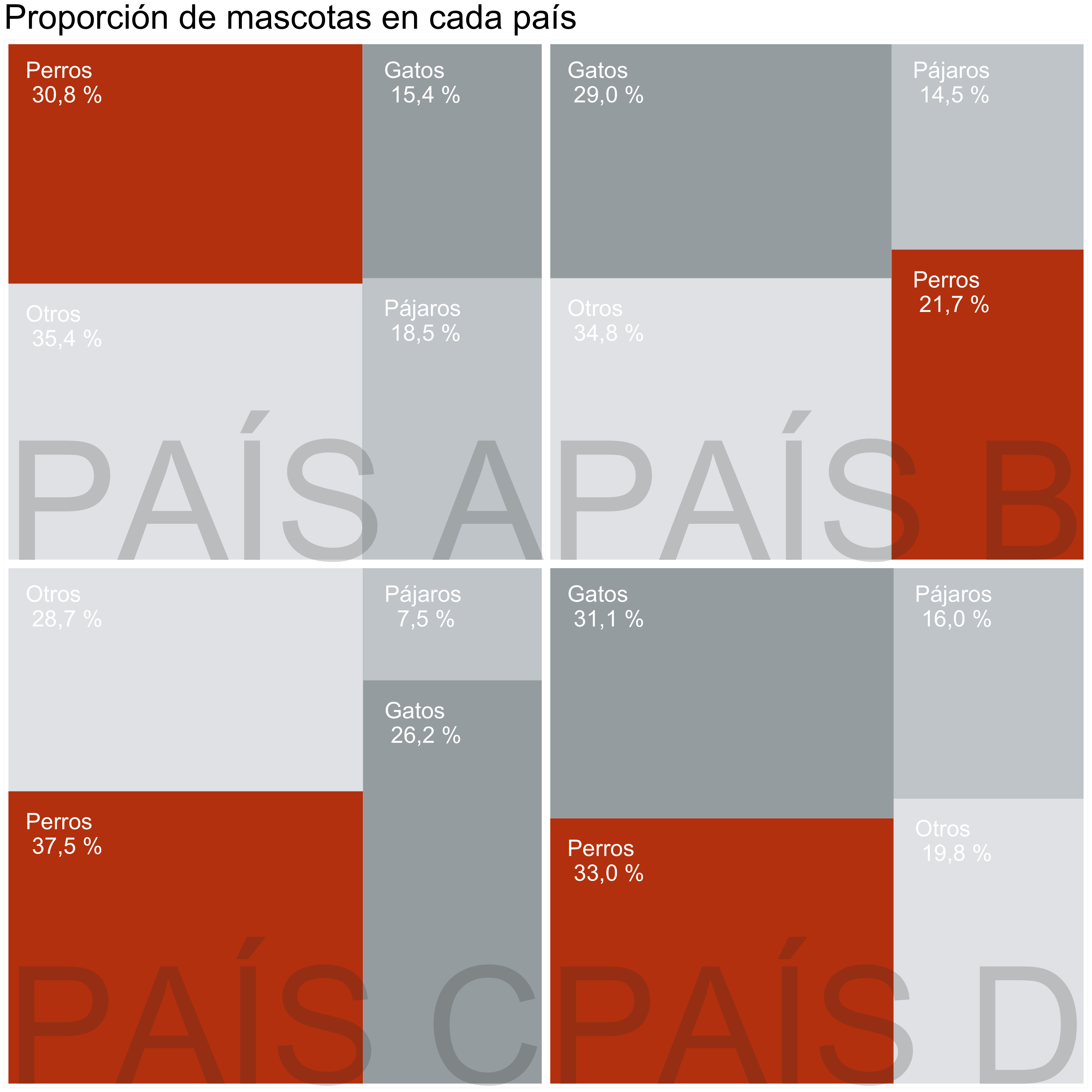
Organización jerárquica de los datos
Solo cuando hay subcategorías anidadas
Cada rectángulo ocupa un área proporcional a la cantidad de datos que representa
Tip
Un buen treemap contiene: valores positivos que forman parte de un todo y que son agrupables por categorías y niveles.❌ Nunca incluyas en tu treemap valores negativos
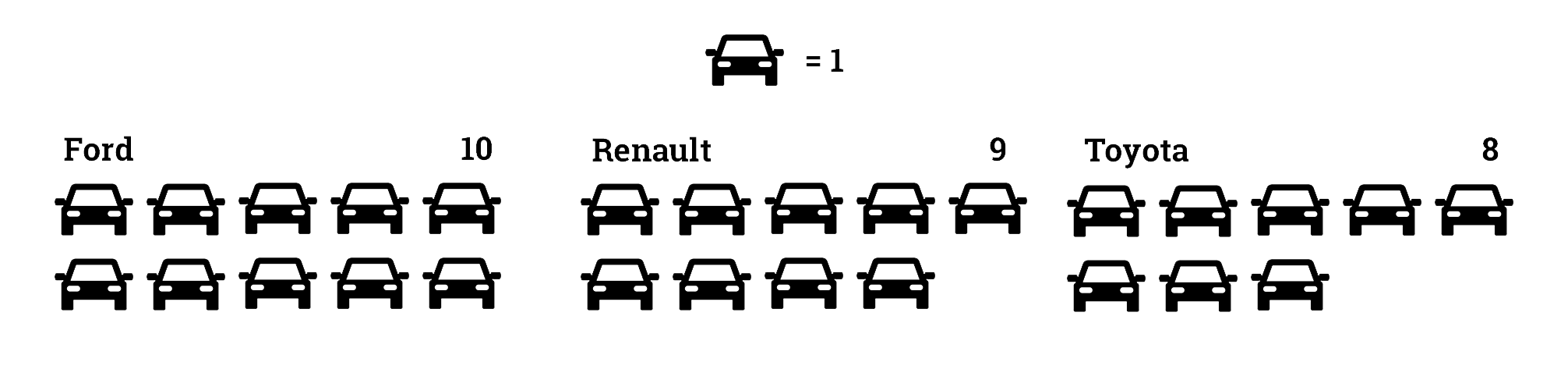
Pictogramas
Los pictogramas ofrecen un vistazo rápido de cantidades y volúmenes, pero no sirven para mostrar datos masivos
Las barras son más eficientes para comparar cantidades discretas
Los iconos deben ser simples, simétricos y funcionar bien en tamaños pequeños
Mala elección

Buena elección

Pictogramas
No deformes los pictogramas para transformarlos en barras/columnas. El tamaño debe ser proporcional en cuanto al área.

Pictogramas
Utiliza unidades naturales.
Asigna un valor al icono y divide los datos en unidades que sean múltiplo de ese valor.
Evita partir los iconos. Si tus datos no encajan con esta división, las barras o las columnas son mejor opción.

Pictogramas
Si los datos que vas a comparar están muy juntos, no uses pictogramas.
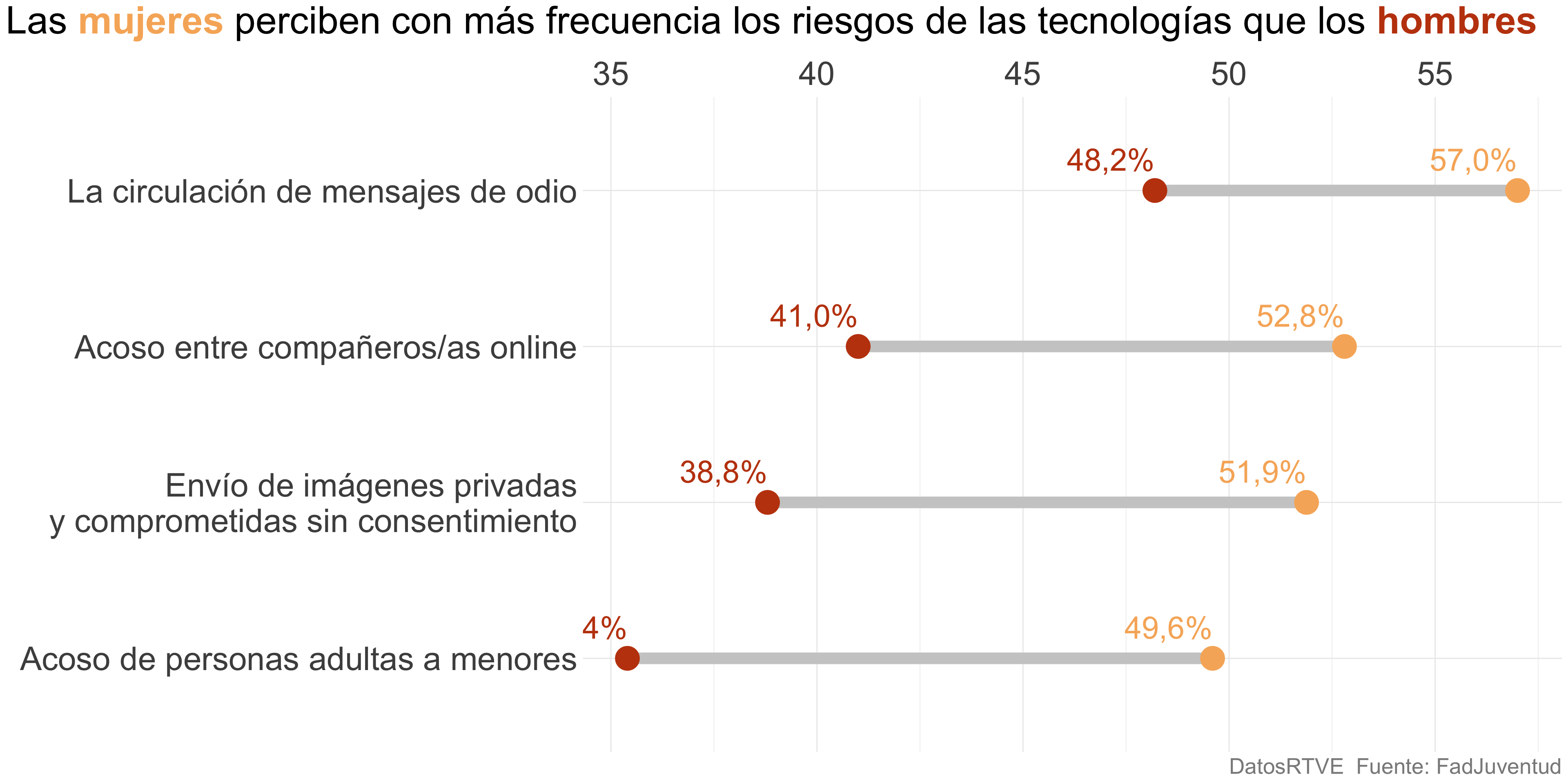
Rangos de puntos
Una buena elección para mostrar la diferencia entre dos variables
Además de una comparación en horizontal, permite comparar en vertical
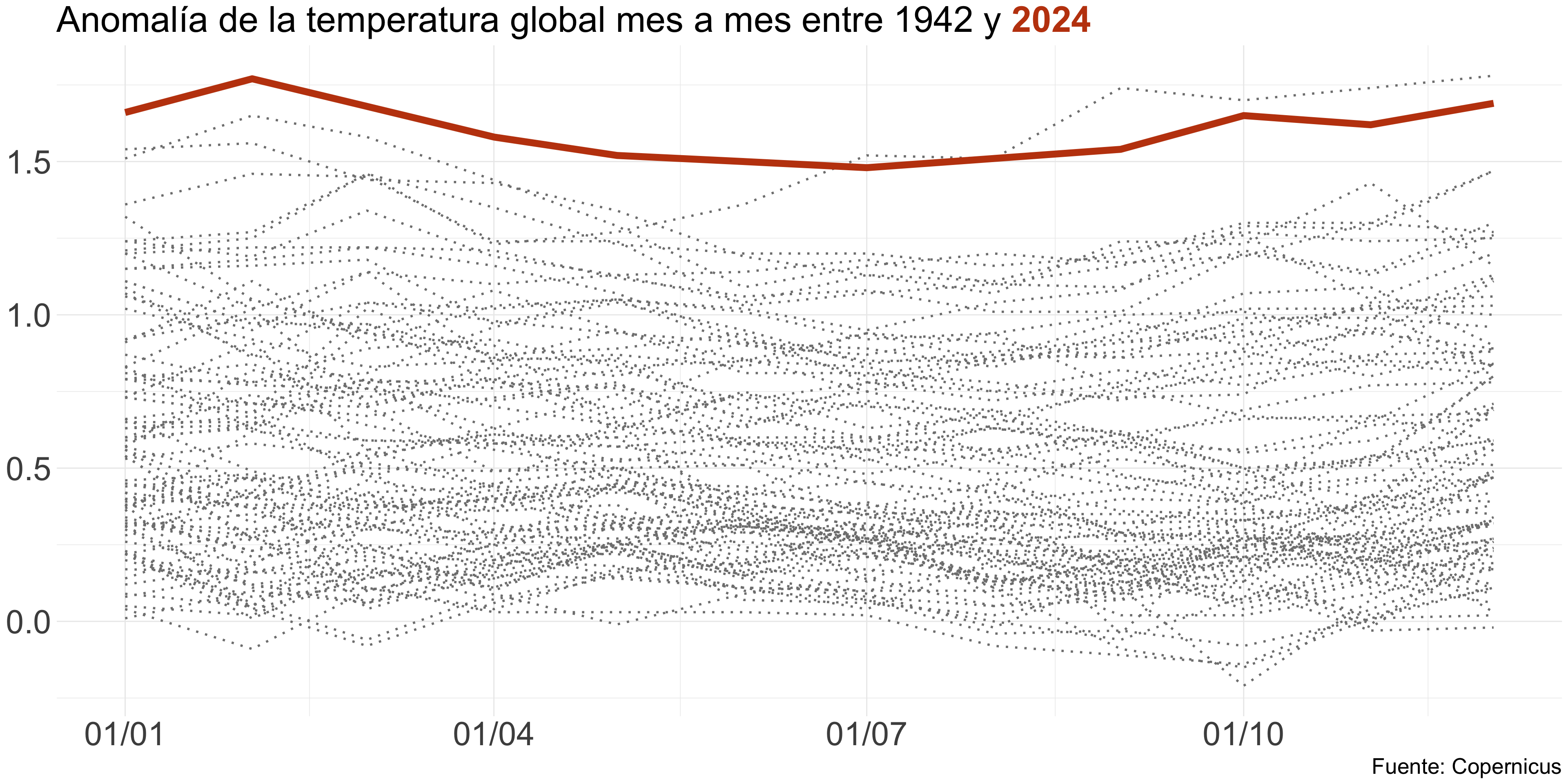
Curvas
Usa gráficos de líneas cuando quieras mostrar la evolución de unos datos
Los gráficos de líneas permiten comparar categorías entre sí
Funcionan con series de datos largas que evolucionan de forma continua
Áreas
- Si las categorías forman parte de un todo, es mejor el gráfico de área
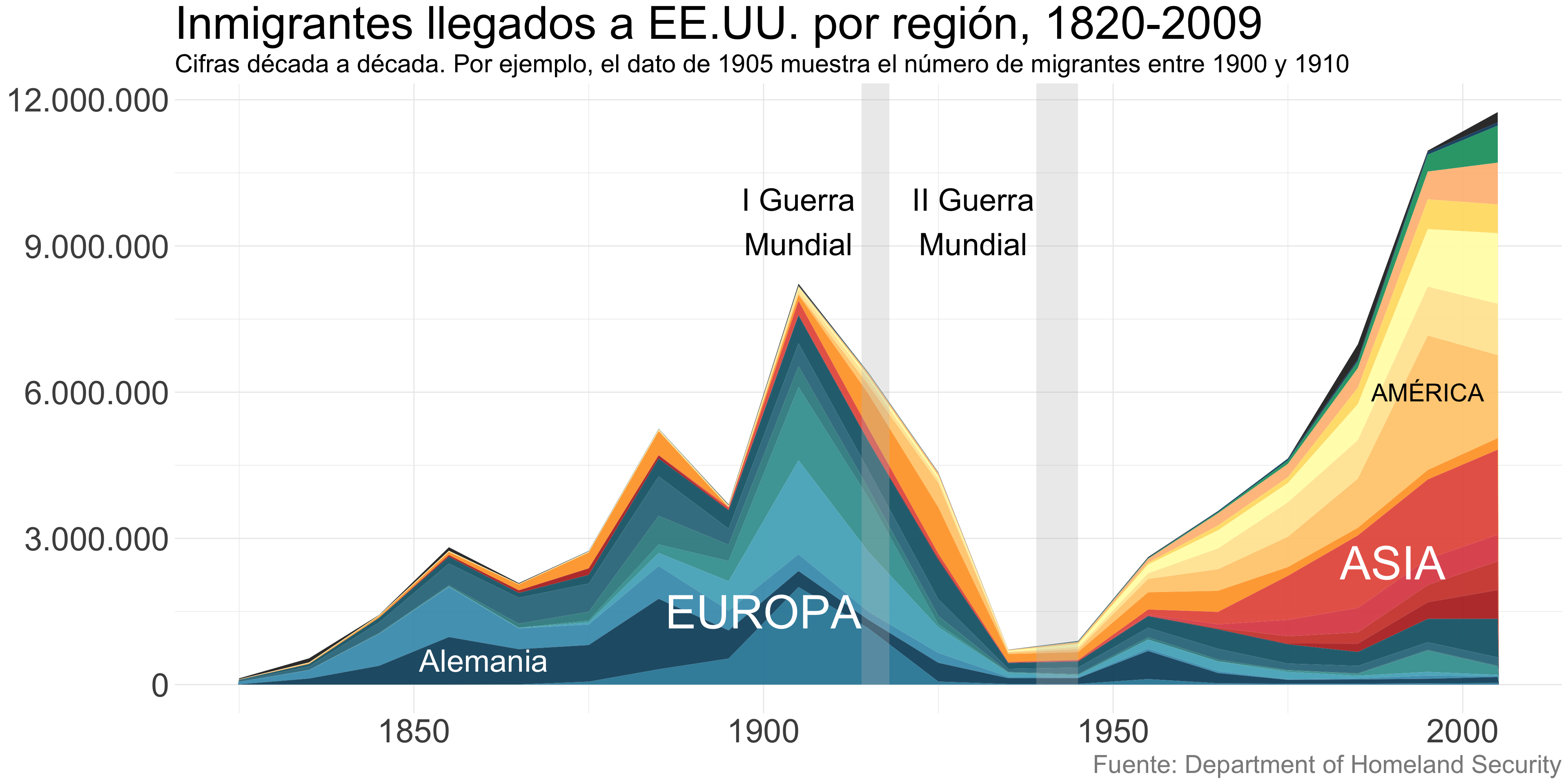
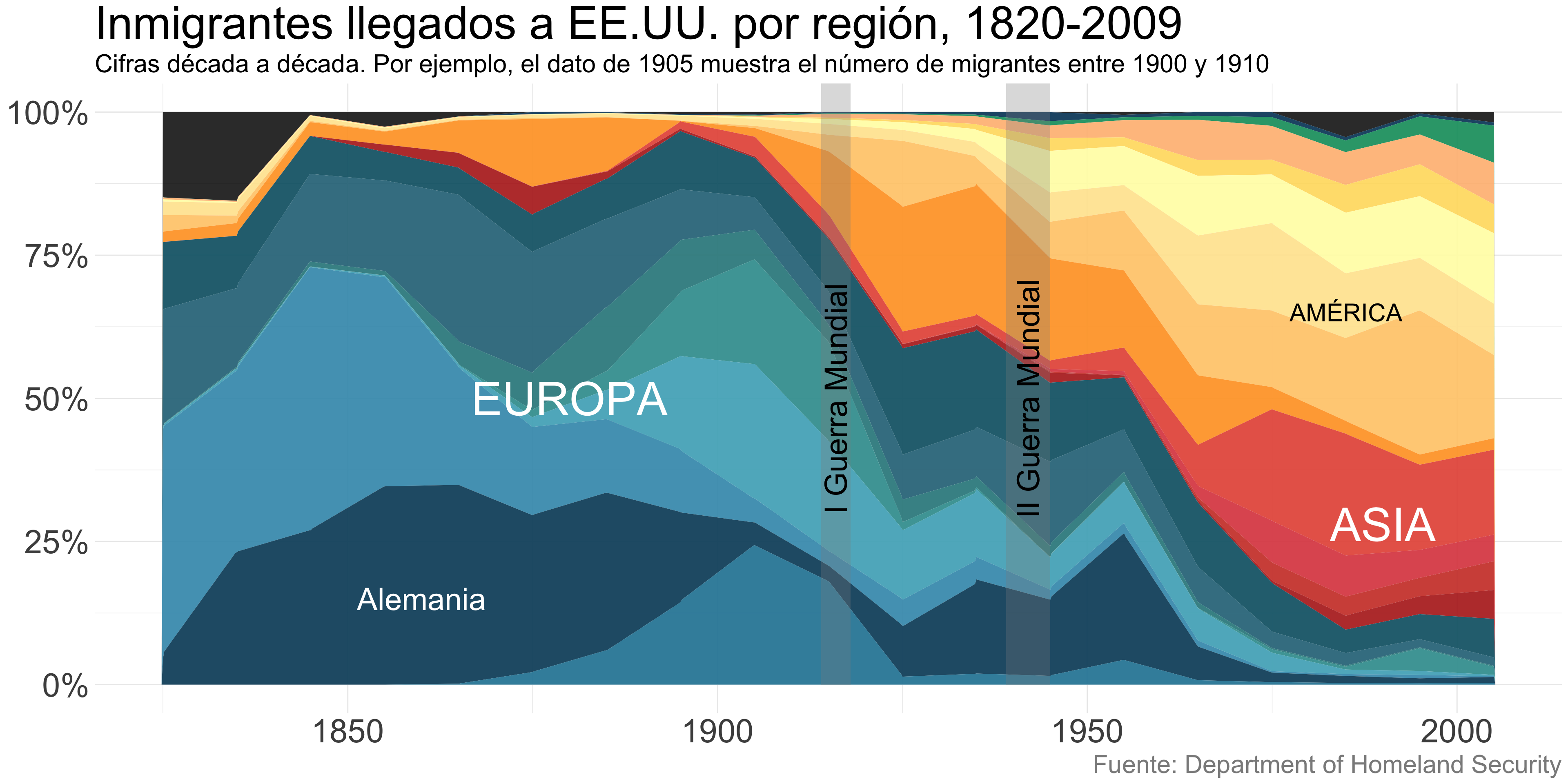
Áreas apiladas
- Apilar los valores absolutos permite que los lectores vean cómo ha cambiado la distribución de las categorías a lo largo del tiempo.
El mundo como 100 personas
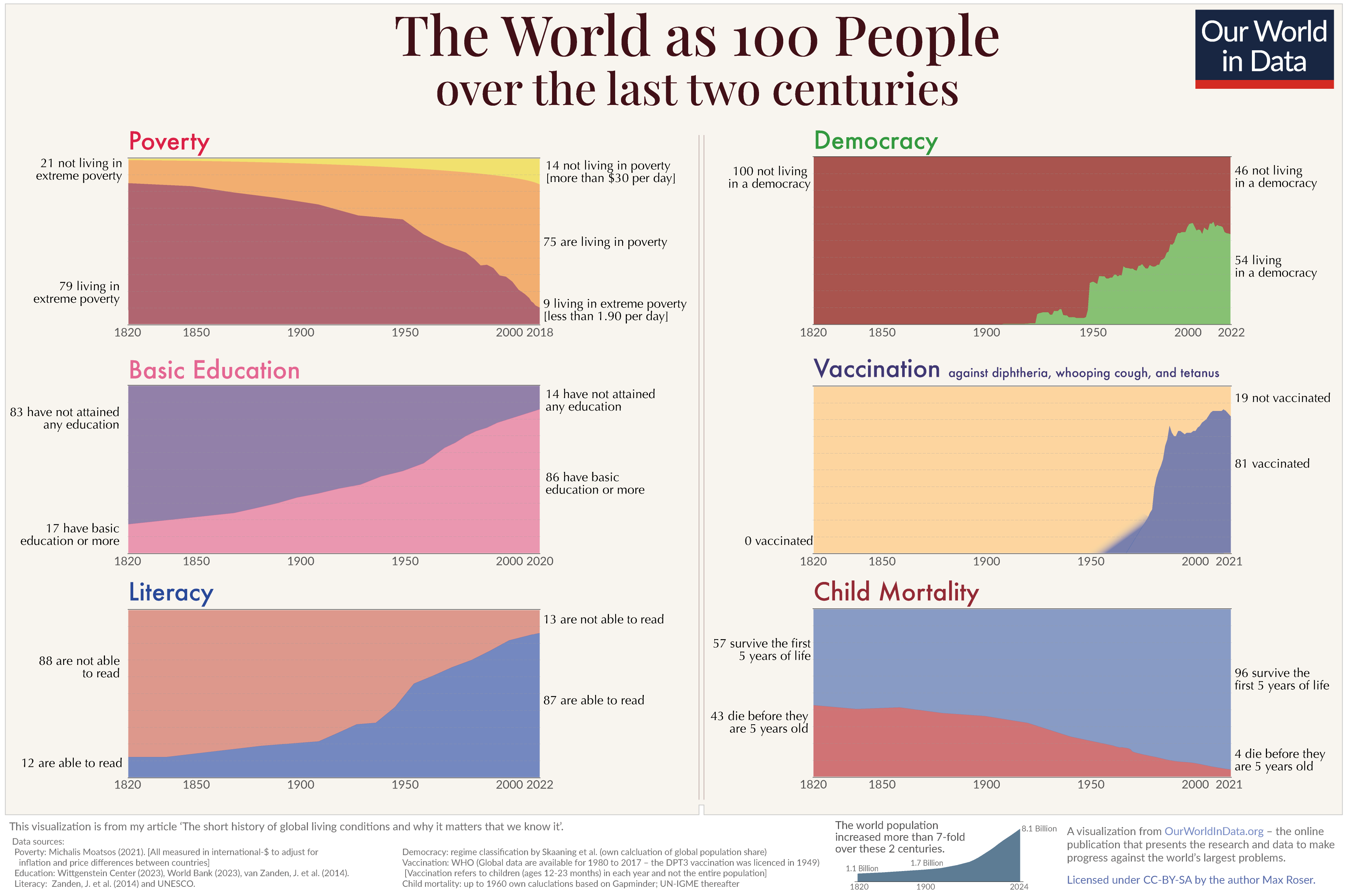
Max Roser
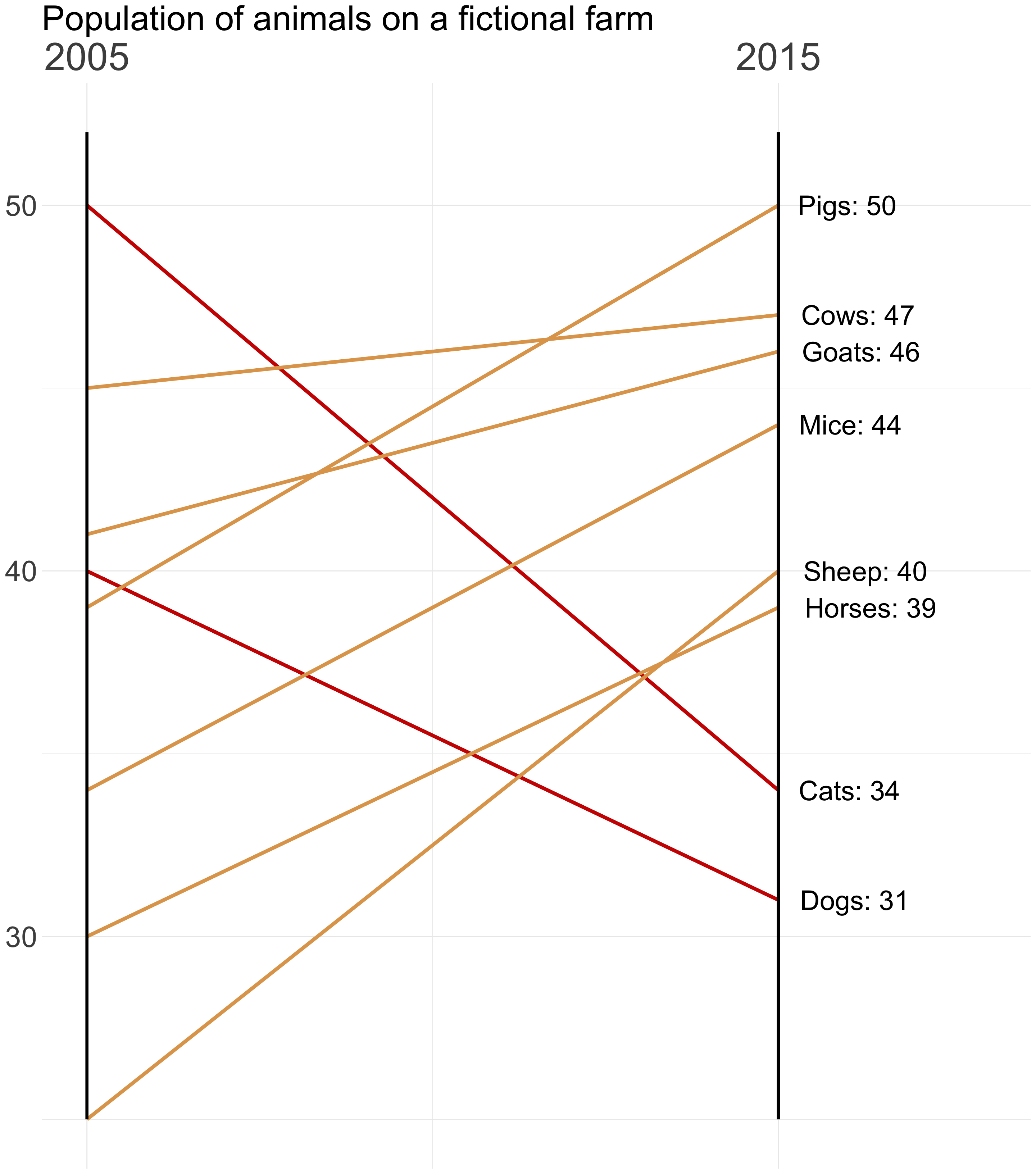
Slopes
Es el mejor gráfico si tienes pocos datos
Pone el foco en el principio y el final del periodo temporal
Permite etiquetar casi todas las líneas
Puedes usar el color para señalar las subidas y bajadas
Variación porcentual
- Otra forma de mostrar la evolución de un dato es visualizando su variación porcentual
Barras divergentes
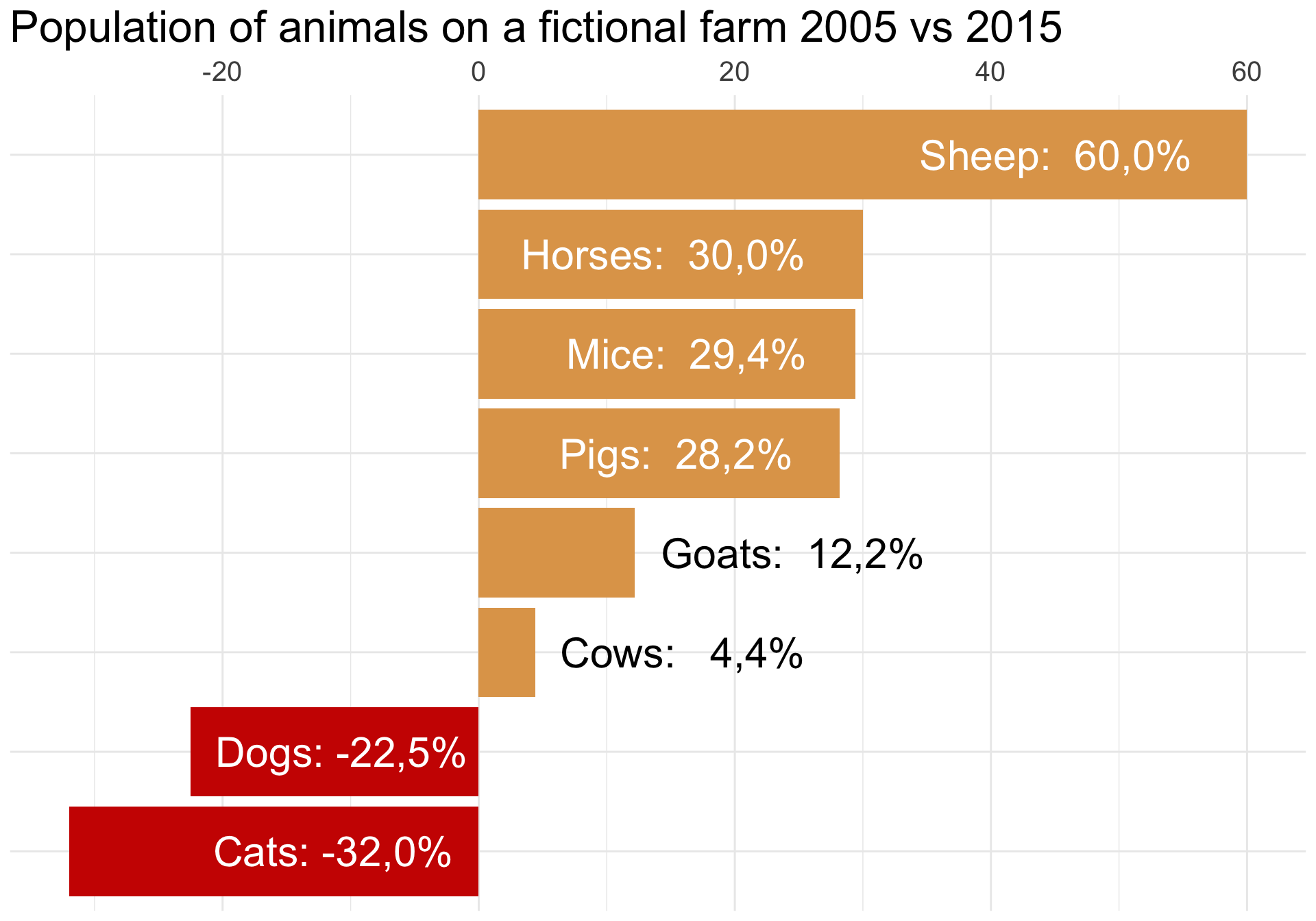
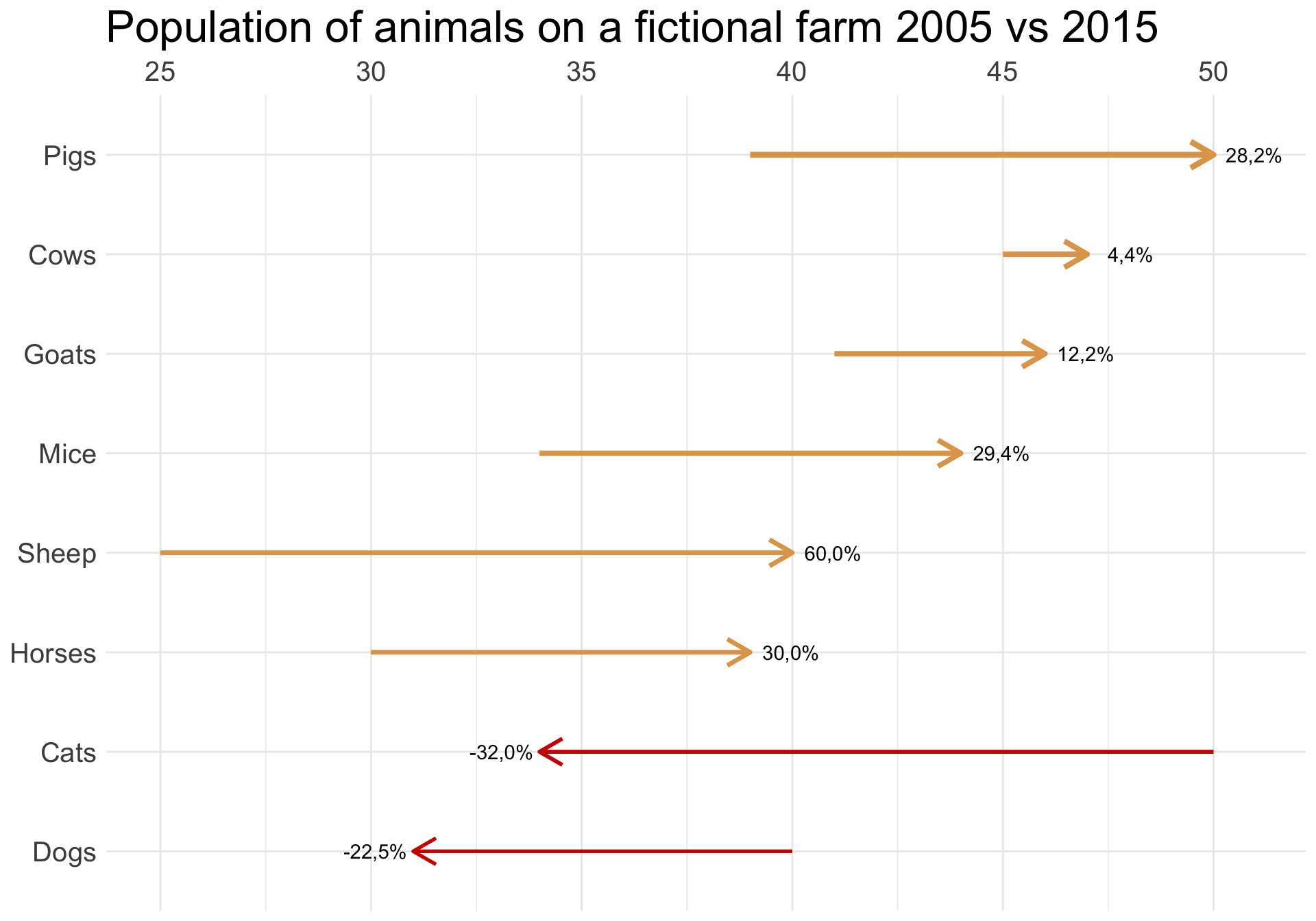
Flechas
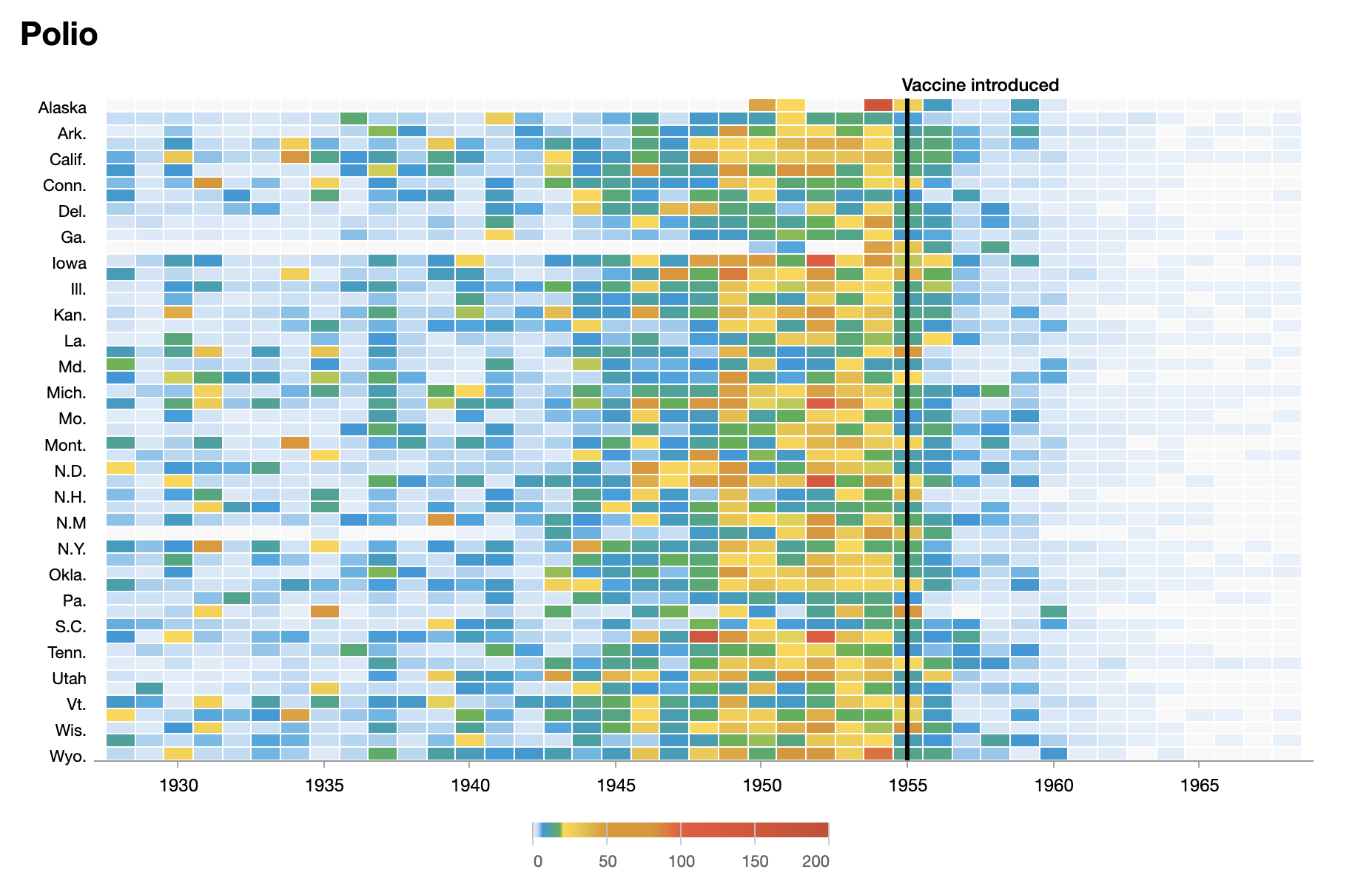
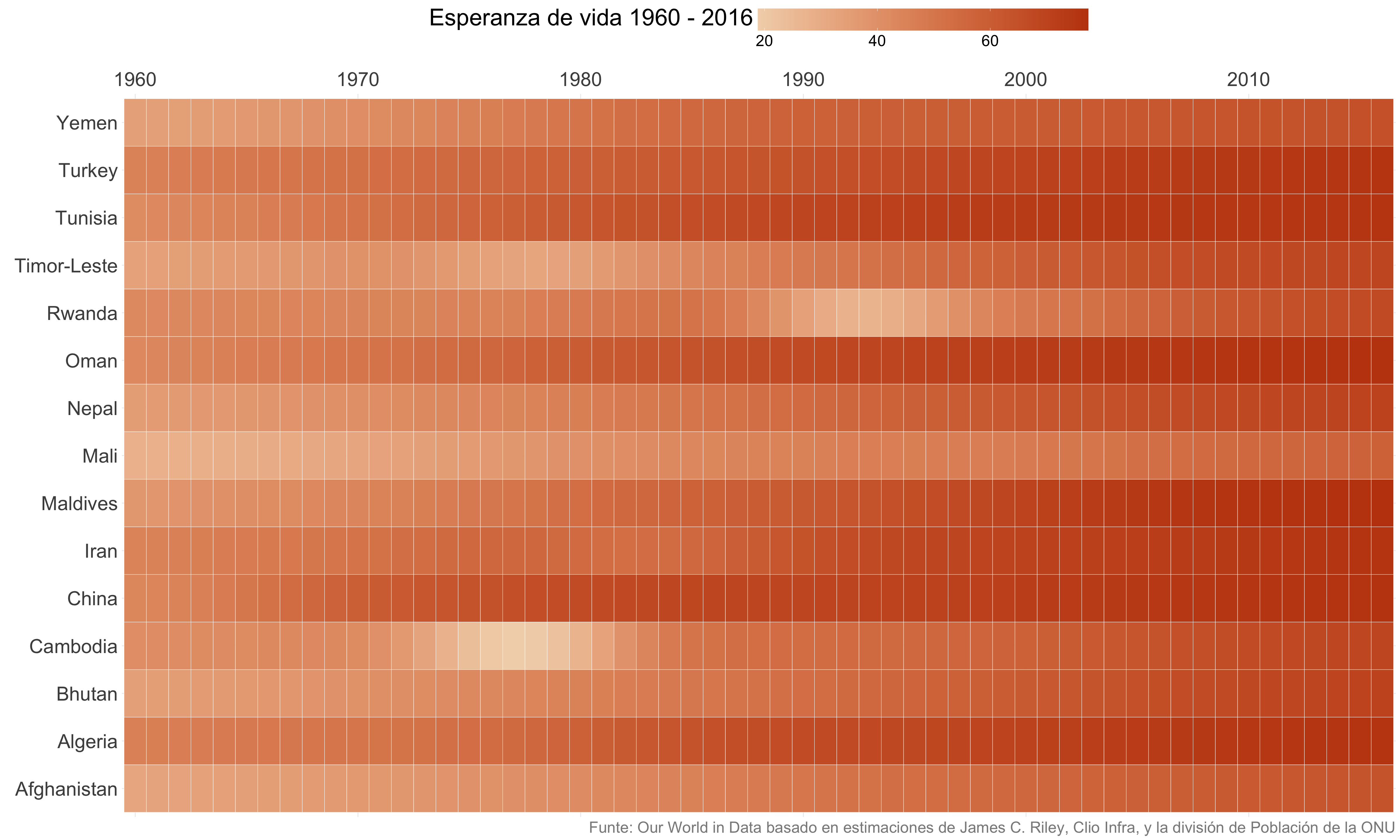
Heatmap (I)
Útiles para mostrar datos agrupados en intervalos
Muestran de un vistazo la evolución de una serie histórica
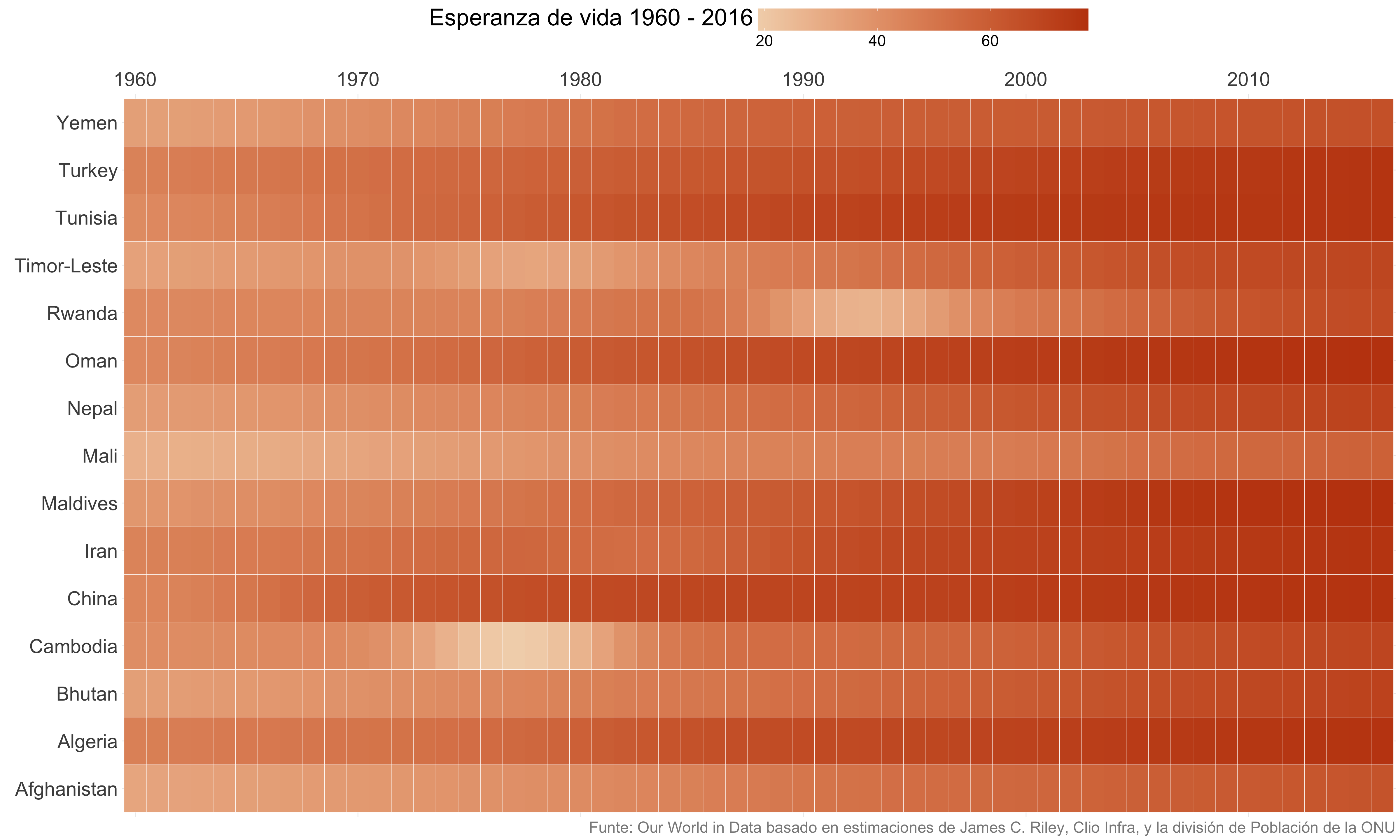
Heatmap (II)
Warning
Comparados con un gráfico de líneas, los heatmaps hacen más difícil cuantificar cada dato por separado
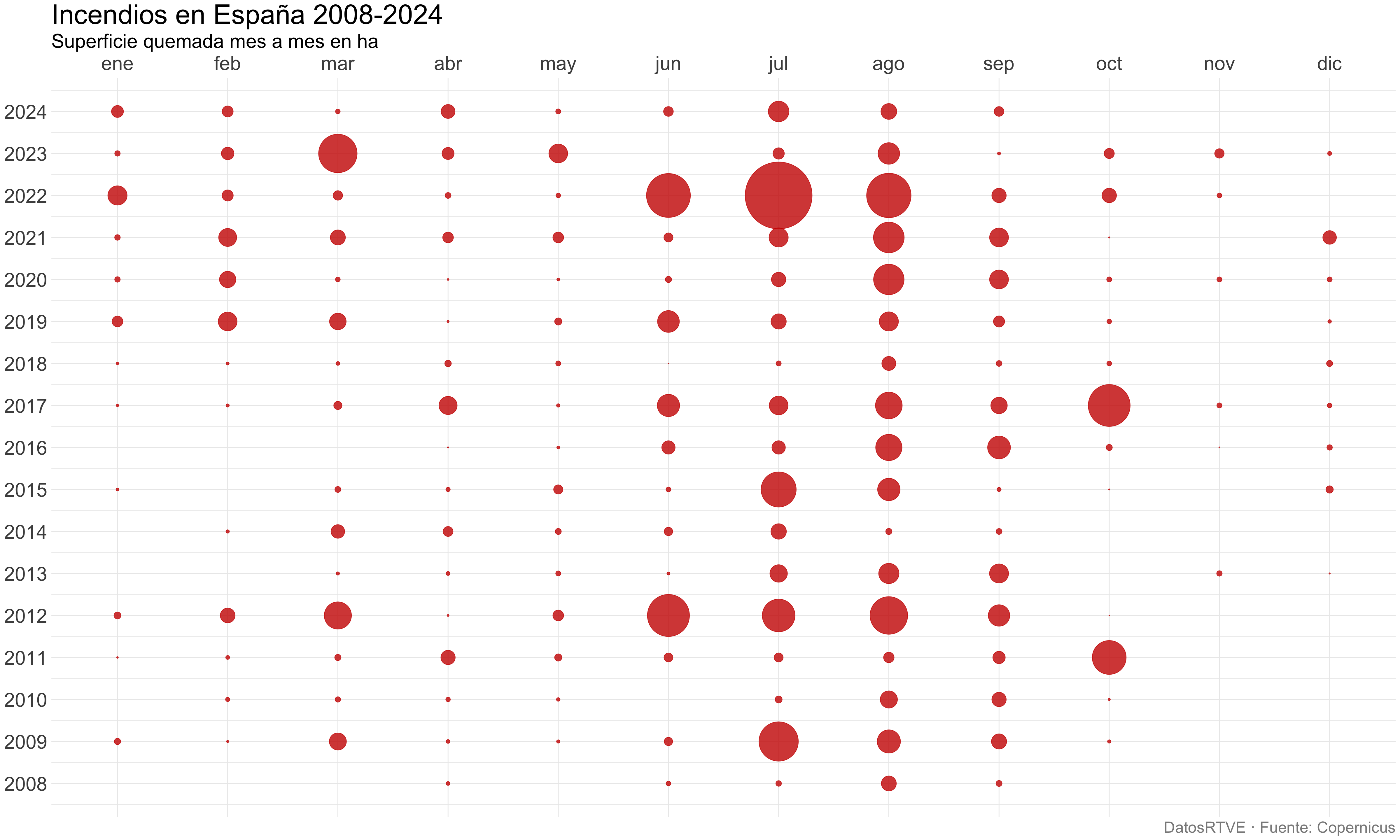
Calendario de burbujas
Eficaces para comparar magnitudes en periodos de tiempo concretos
Muy útiles para datos de desastres naturales
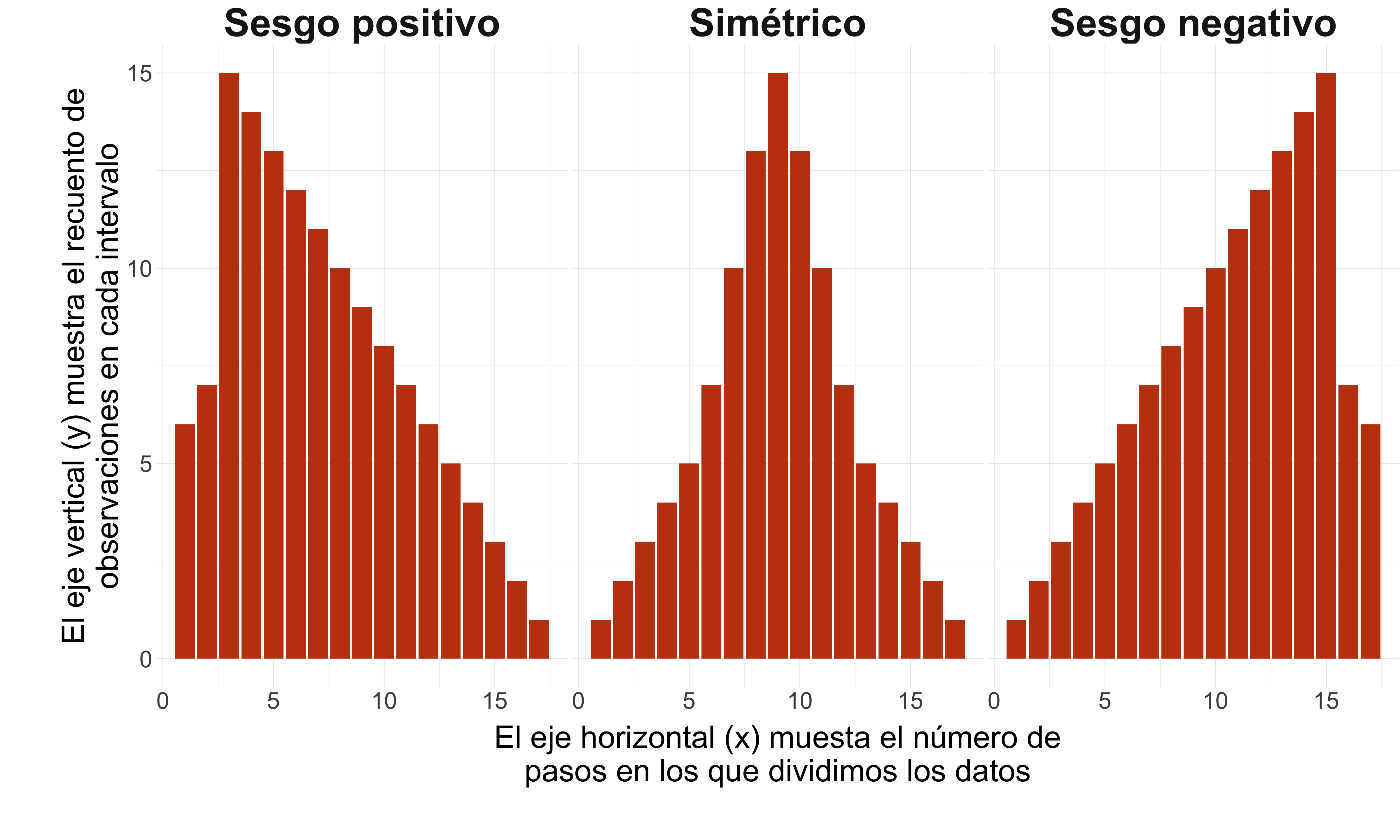
Histogramas
- Su forma nos indica la distribución de los datos
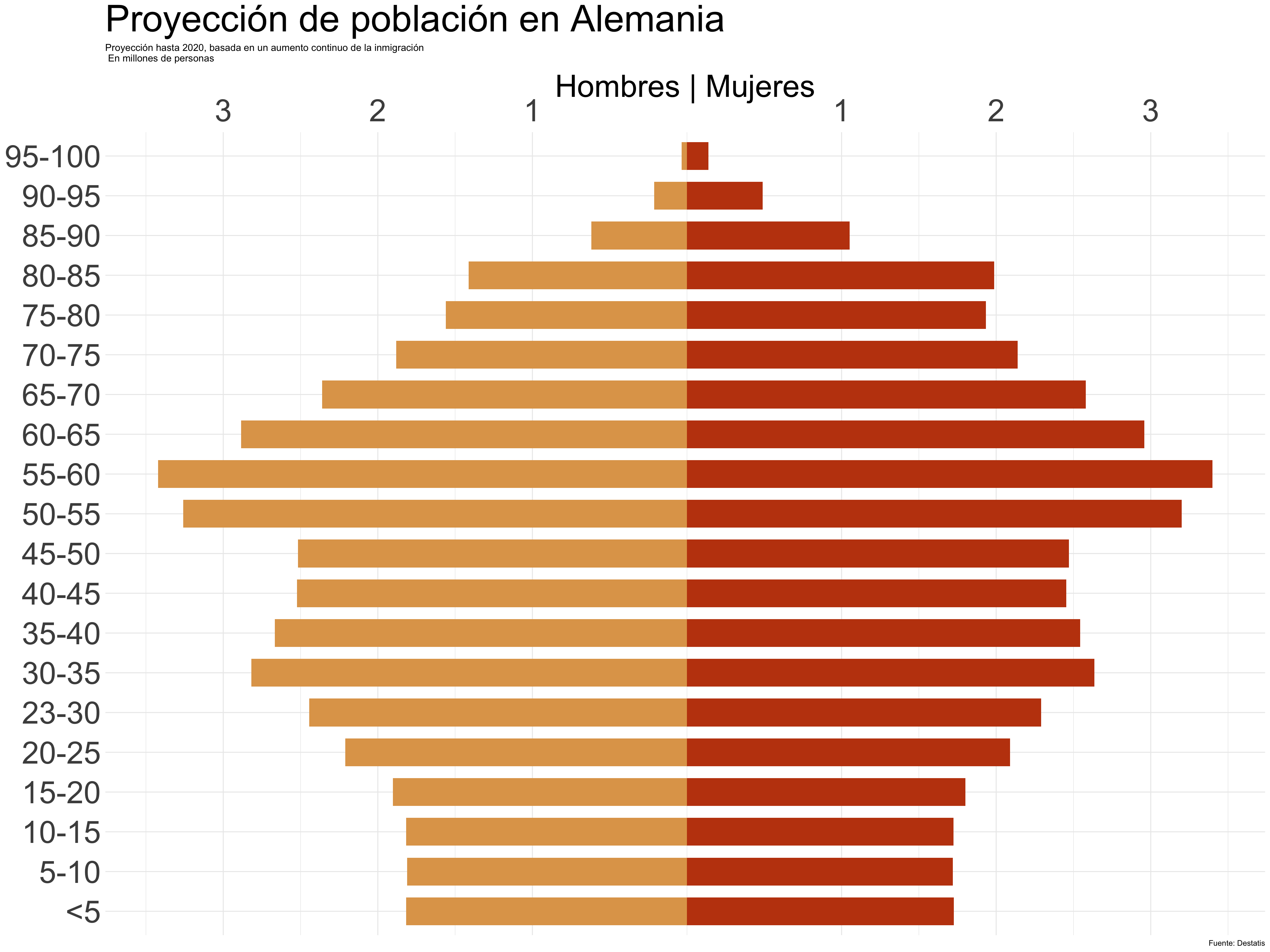
Pirámides de población
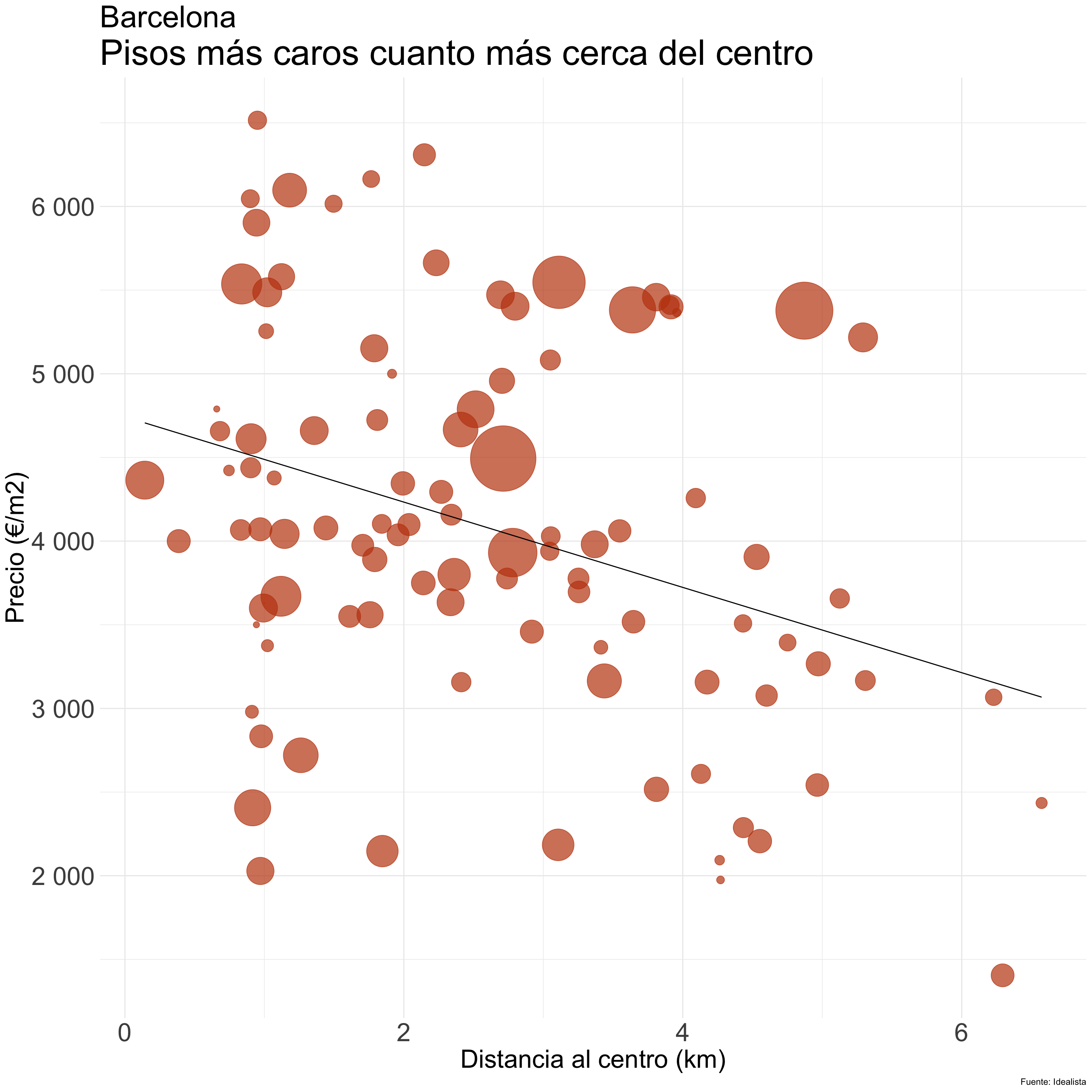
Diagramas de dispersión o scatterplots
La correlación nos permite ver hasta qué punto dos sucesos pueden estar relacionados.
Cada punto está situado en las coordenadas de sus valores “x” e “y”.
Por convención, el eje “x” se reserva para la variable explicativa (independiente) y el “y” para la que se quiere explicar (dependiente).
Ojo: situar una variable en cada eje no demuestra que una cause la otra.
Gráficos
Mapas
Localizadores
Esquemas
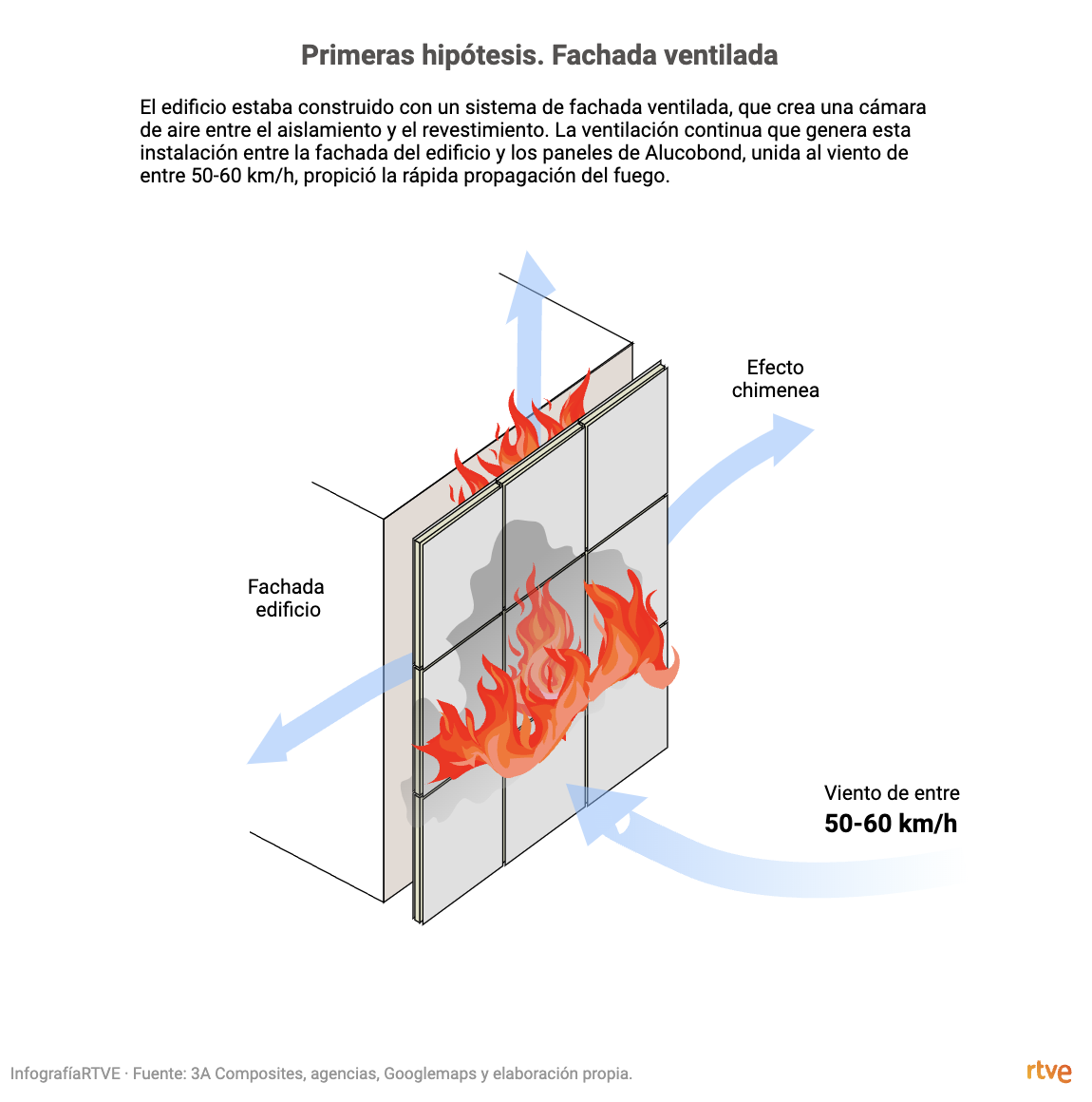
Ilustración fáctica
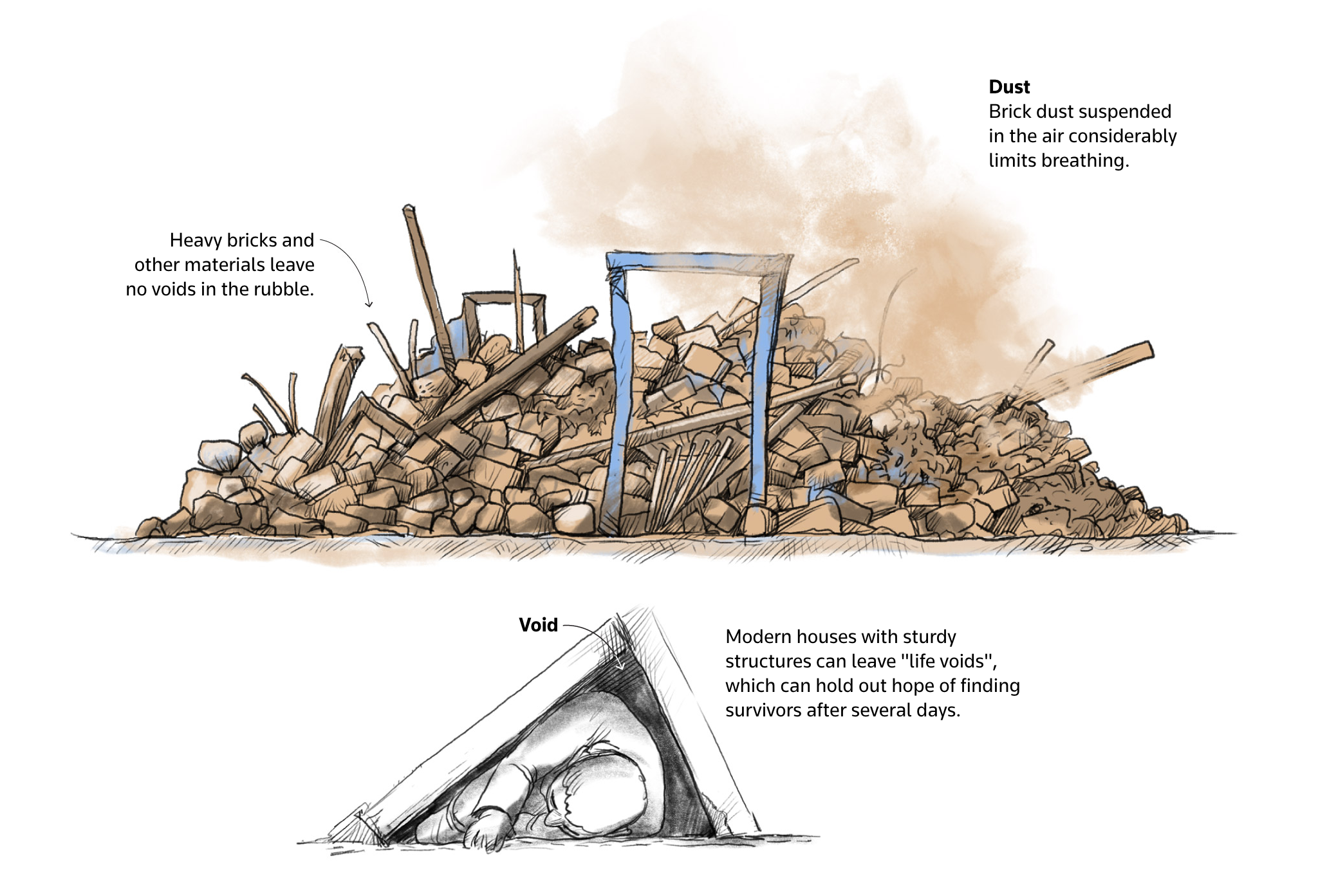
Ilustración decorativa
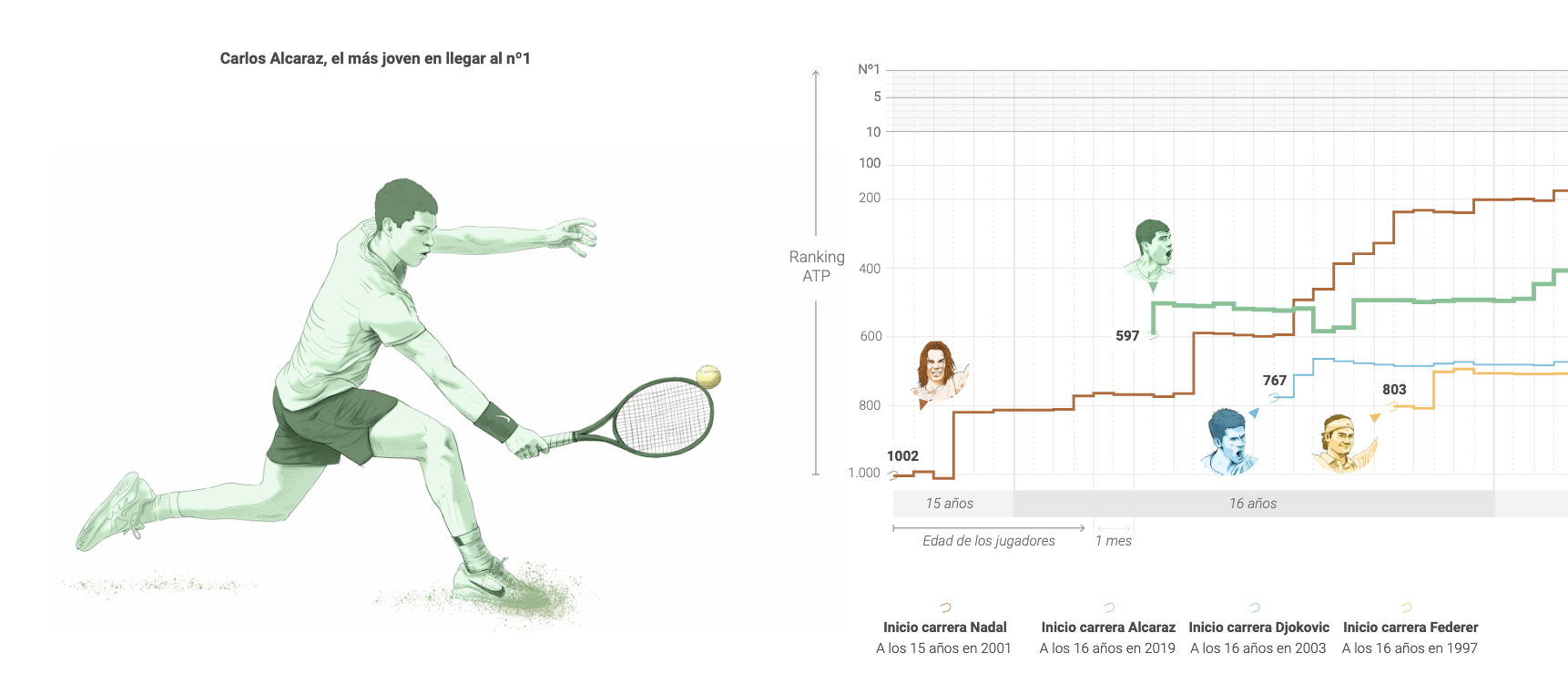
Interactividad
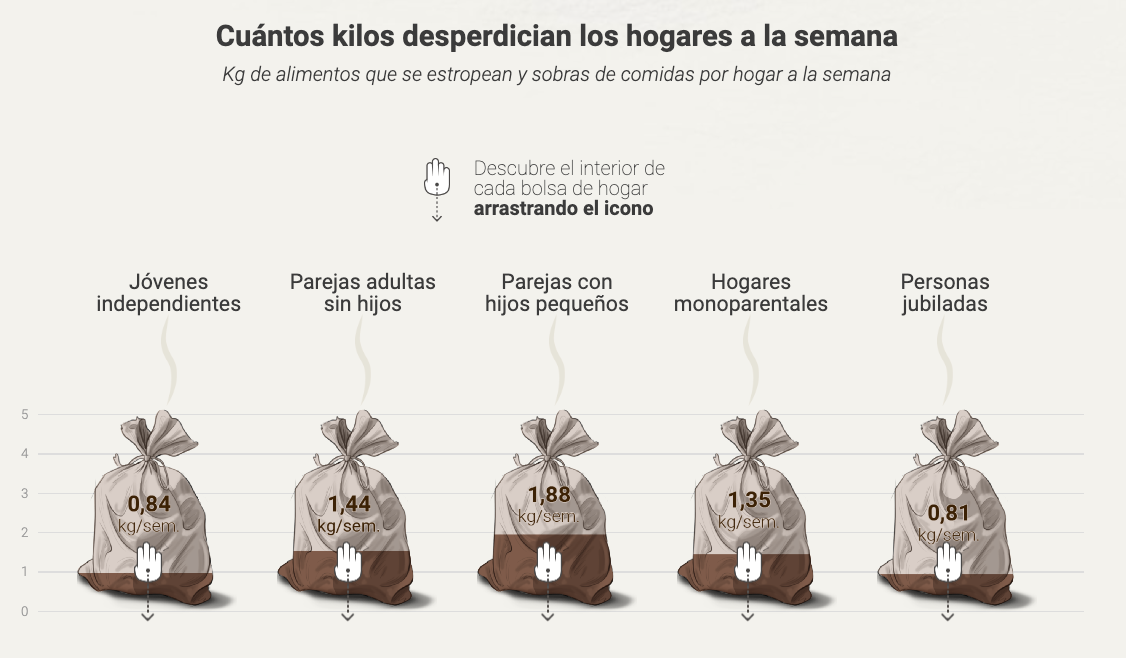
Animación, vídeo y sonido
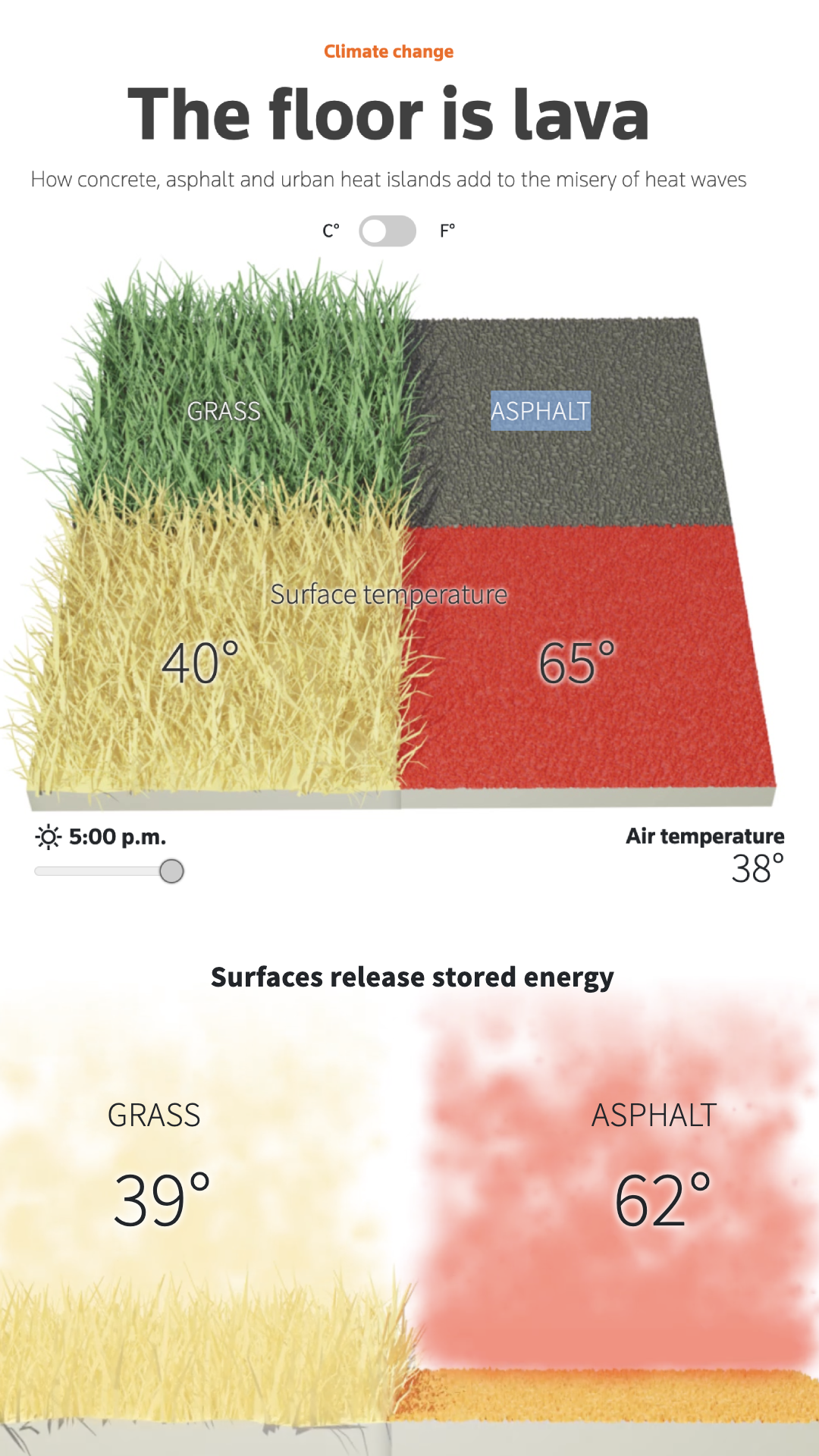


Periodismo inmersivo
Realidad virtual, realidad aumentada y 3D



Scrollytelling
Narrativa cohesiva de eventos a través del tiempo en la que el usuario avanza mediante el scroll.
Del boceto…
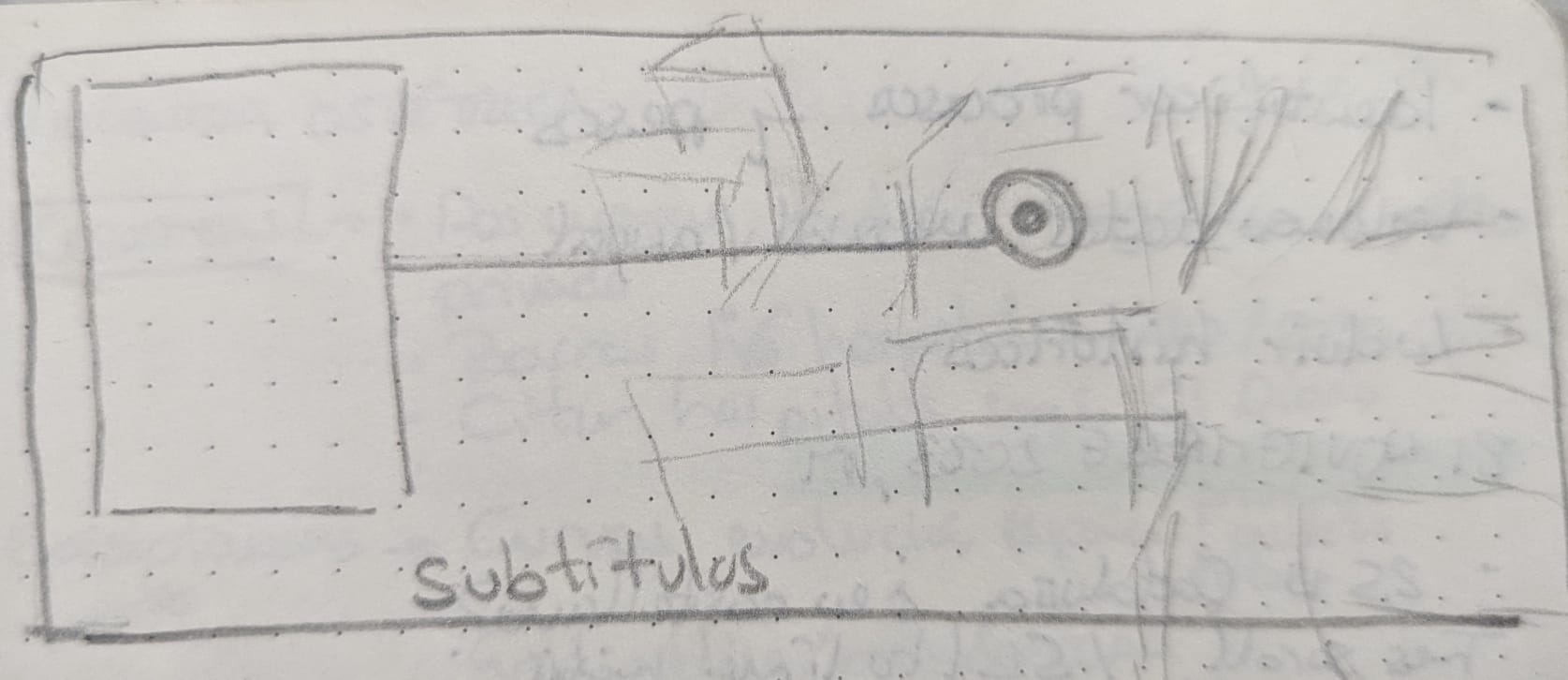
…al resultado

No uses demasiados colores
- Si tu gráfico necesita más de siete colores, considera utilizar otro tipo de visualización o agrupar los datos en nuevas categorías.

Mantén la consistencia…
- Sé consistente con el uso del color en todos tus gráficos.
…y la coherencia visual
- Y mantén la coherencia visual del conjunto.

Tres páginas del The South China Morning Post
Pon el foco en lo importante
- A veces, el gris nos puede ayudar a ofrecer contexto sin abrumar.
Los colores tienen significado
- Usa el color de manera intuitiva y ten en cuenta su significado cultural para la audiencia.

El rosa y azul está bien, pero…
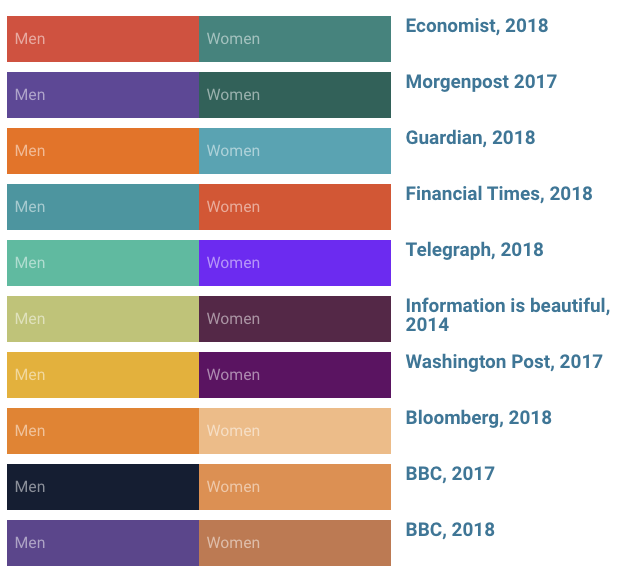
Variables continuas y categóricas
- No uses gradientes de color para variables categóricas, y viceversa.
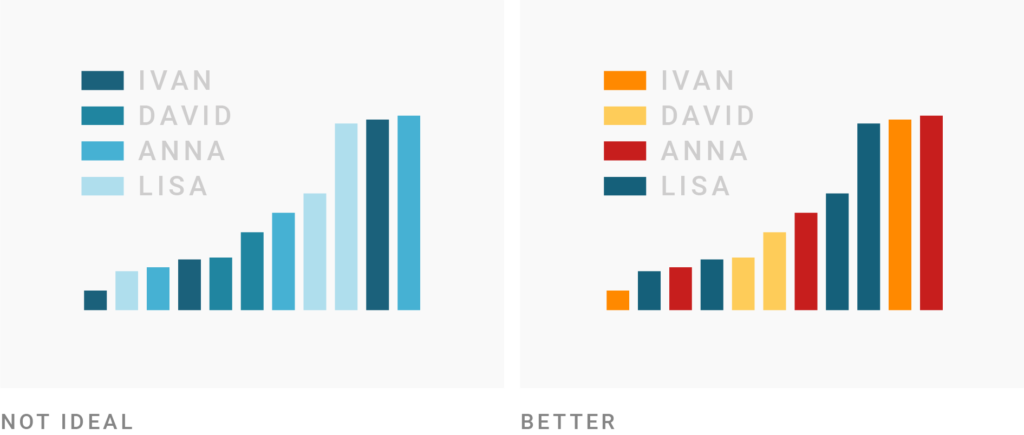
Grupos y subgrupos
- Puedes usar gradientes para distinguir subgrupos dentro de categorías.
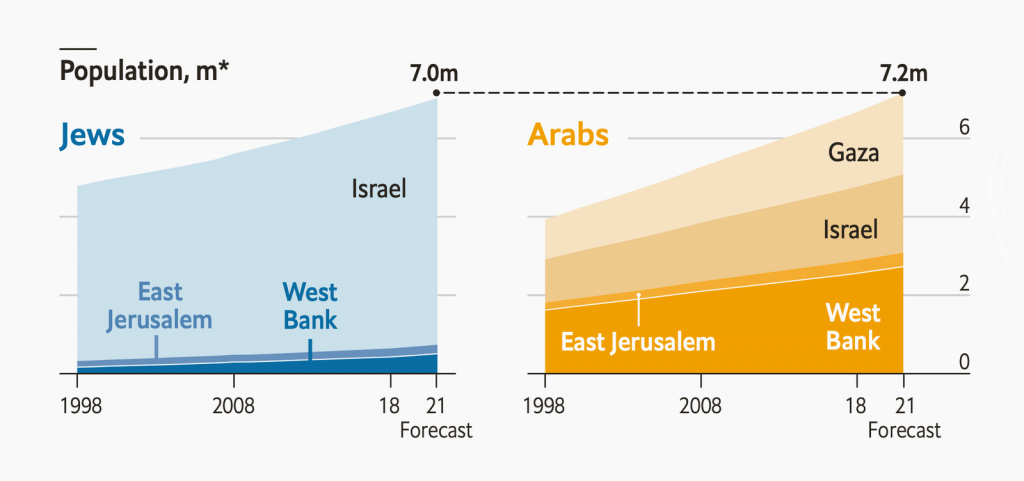
Población en territorios ocupados por religión (The Economist)
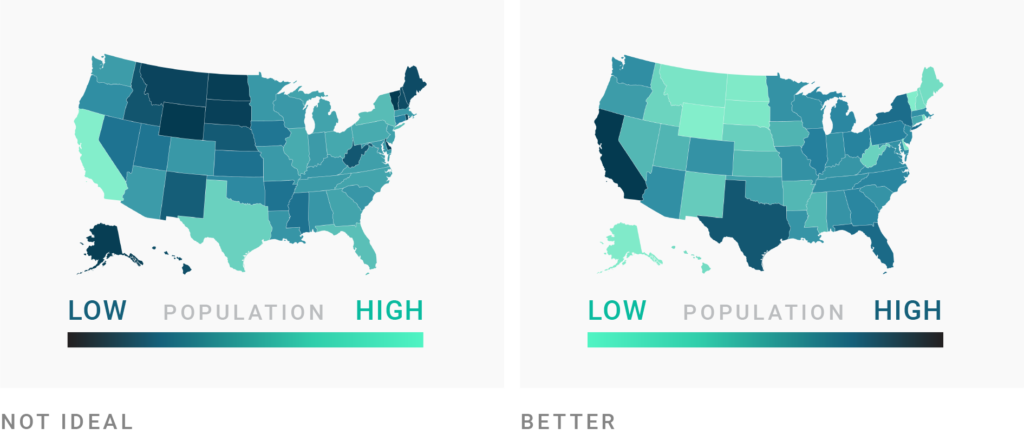
La intensidad del color también informa
- Usa colores claros para valores bajos y oscuros para valores altos.
Cada dato requiere una escala de color

Secuencial. Cuando tengas datos cuantitativos y quieras destacar los valores más altos
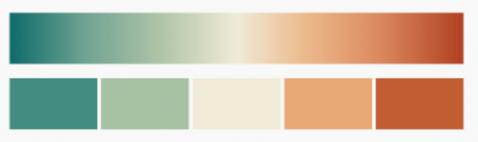
Divergente. Cuando tengas datos cuantitativos y quieras poner el foco en los dos extremos de la escala

Cualitativa o categórica. Cuando los datos no son cuantitativos
Escalas
- Usa escalas divergentes cuando haya un punto medio con un significado. Puede ser 0, 50%, la media o la mediana, un objetivo a alcanzar… Y ten en cuenta que pone el énfasis en los extremos.
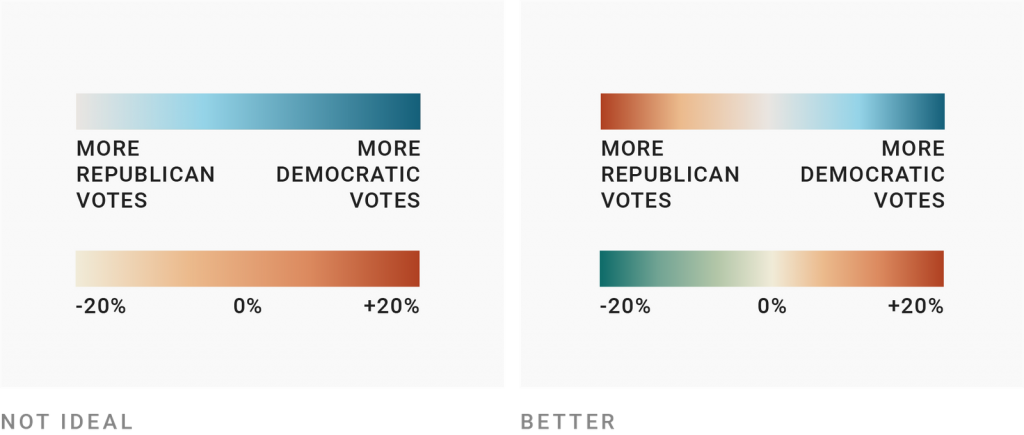
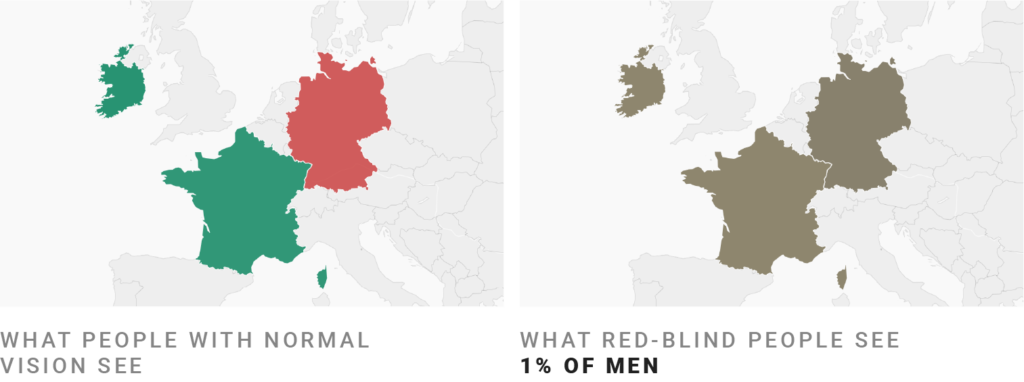
Ten en cuenta a las personas daltónicas (I)
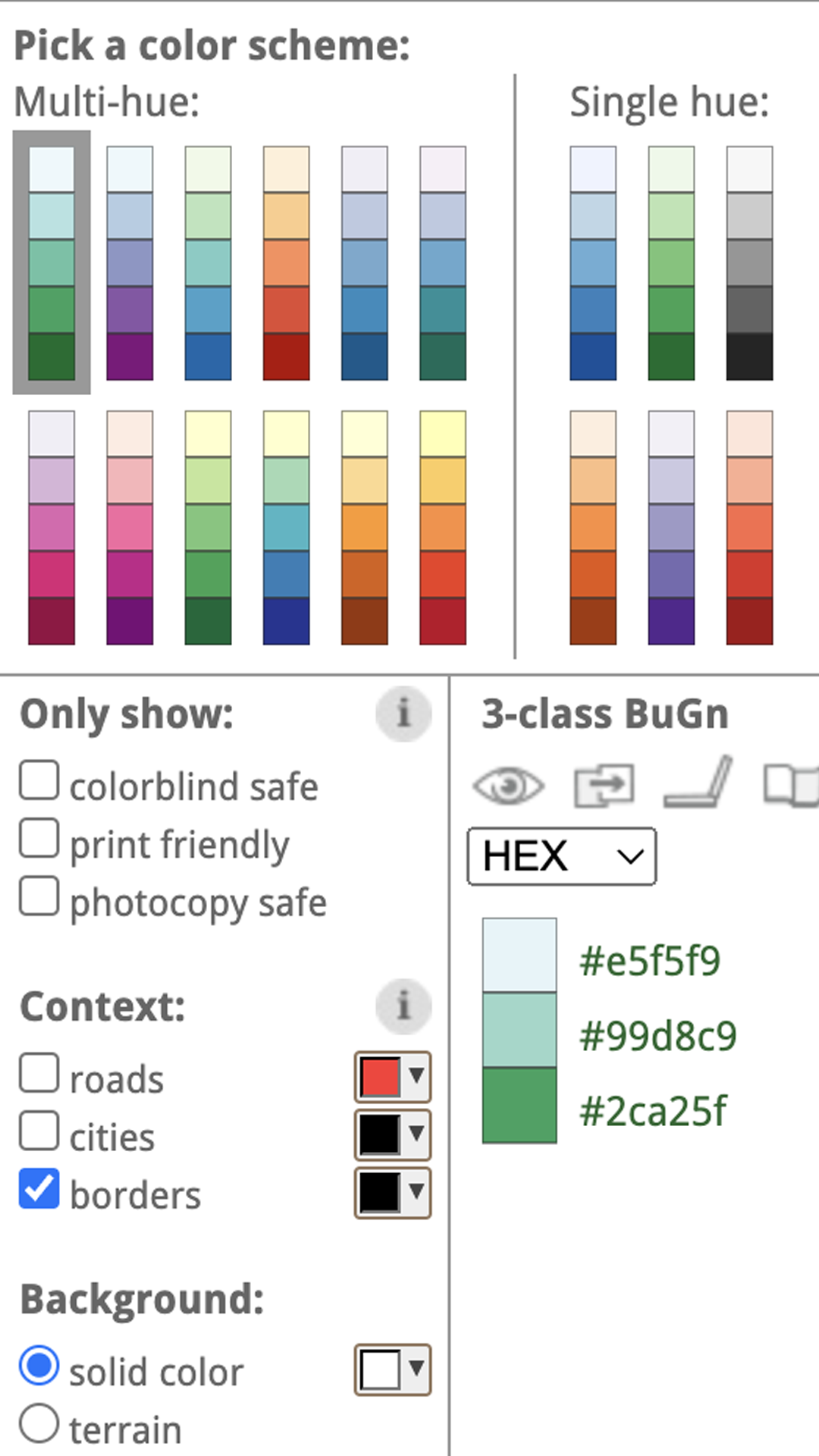
Tres herramientas para crear paletas de color

Sistemas de coordenadas (II)
Algunas consideraciones sobre los sistemas de coordenadas:
Representan la superficie de la Tierra y utilizan puntos para representar la información geográfica.
Sus líneas de referencia son curvas.
Cada punto se localiza utilizando solo dos dimensiones: latitud y longitud.

Proyecciones (II)
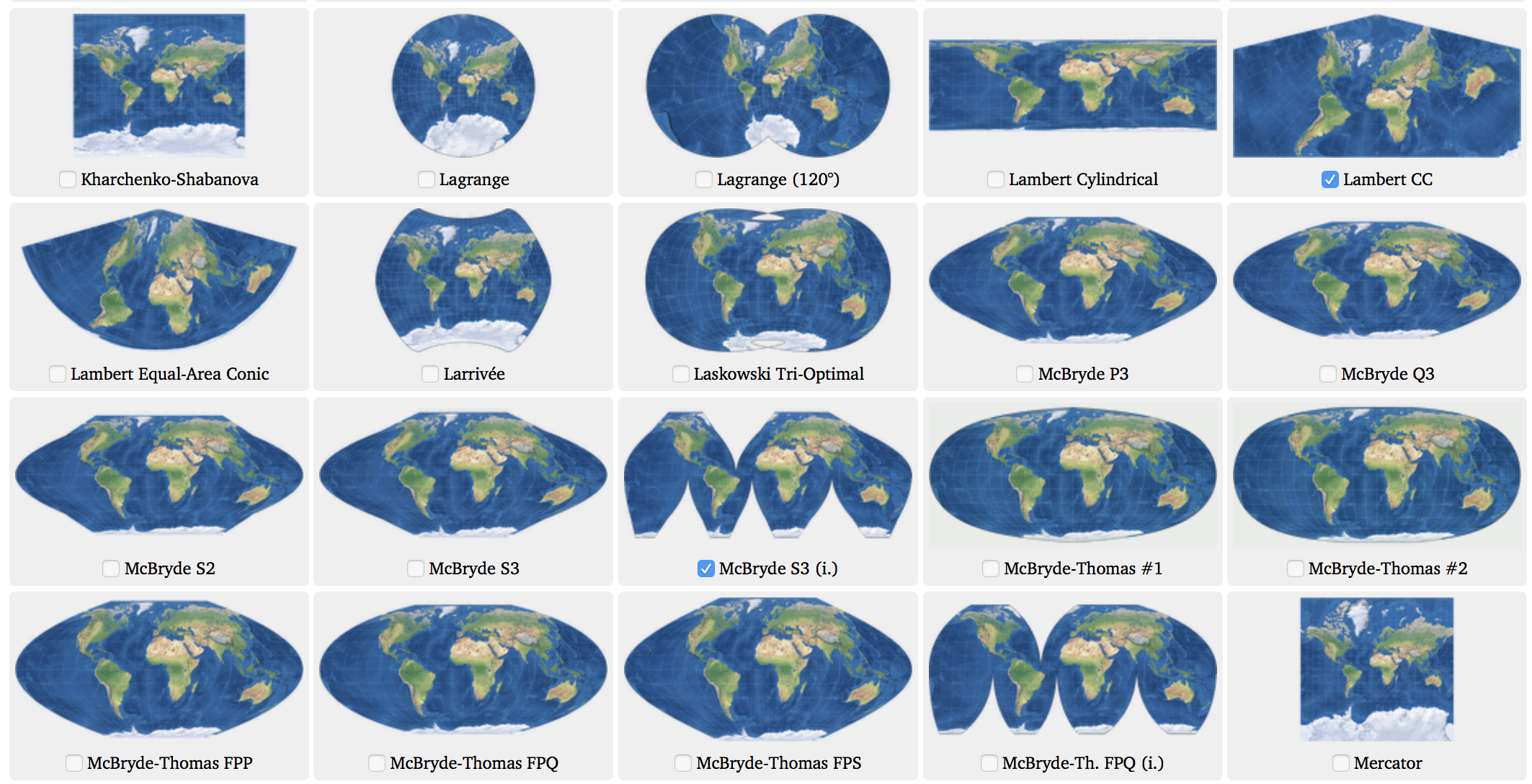
Geo Awesomeness
Datos espaciales y geométricos (I)
Es la información que describe la localización y la forma de un elemento en el mundo real. Puede ser de distintos tipos:
Vectores: ubicaciones y extensiones geográficas discretas.
Raster: ubicaciones aproximadas asignando cada una a las celdas de una cuadrícula o matriz. Por su reducido tamaño, sirven para representar variaciones continuas de los atributos.
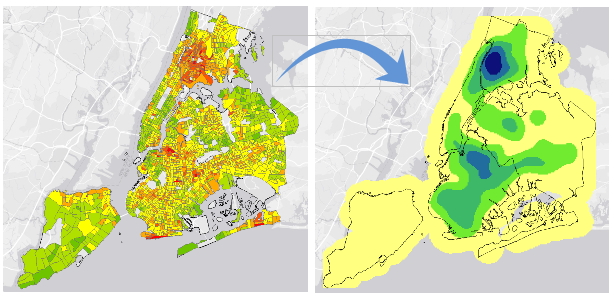
Azavea
Datos espaciales y geométricos (II)
Tres tipos de vectores
Puntos  Tienen ubicación pero no extensión (oficinas de correos).
Tienen ubicación pero no extensión (oficinas de correos).
Líneas 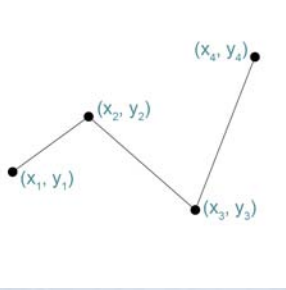 Representan una geometría lineal a partir de puntos conectados (fronteras).
Representan una geometría lineal a partir de puntos conectados (fronteras).
Polígonos 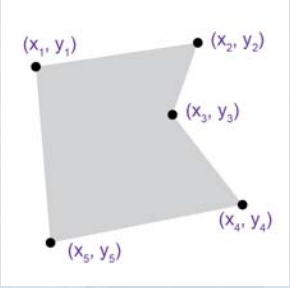 Áreas completamente encerradas por líneas cuyos puntos inicial y final coinciden (países, provincias…).
Áreas completamente encerradas por líneas cuyos puntos inicial y final coinciden (países, provincias…).
Datos espaciales y geométricos (III)
Fuentes de datos cartográficos:
⛏️ Google (Universidades, organismos internacionales, investigadores…)
El formato importa 
QGIS y Mapshaper


Tres tipos de mapas
Mapas coropléticos 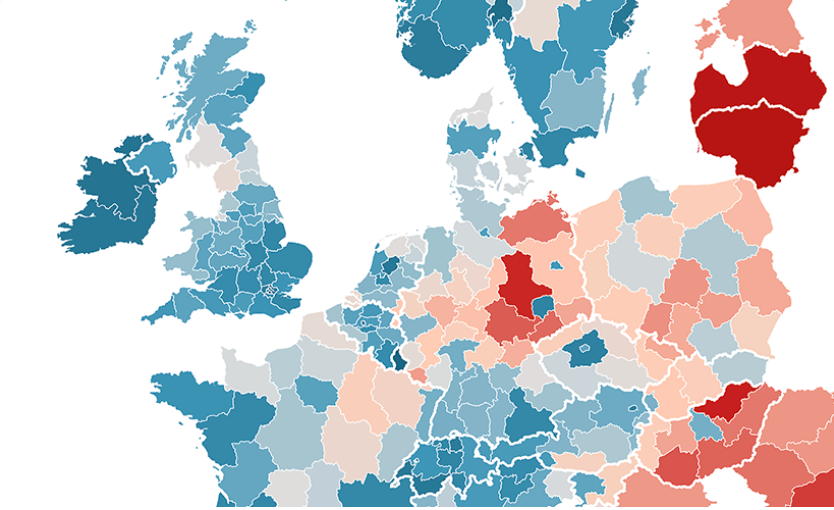
Mapas de símbolos 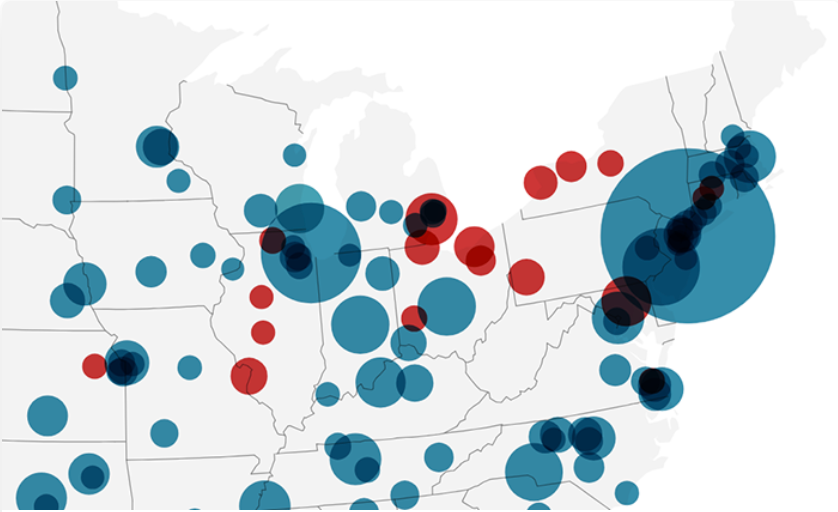
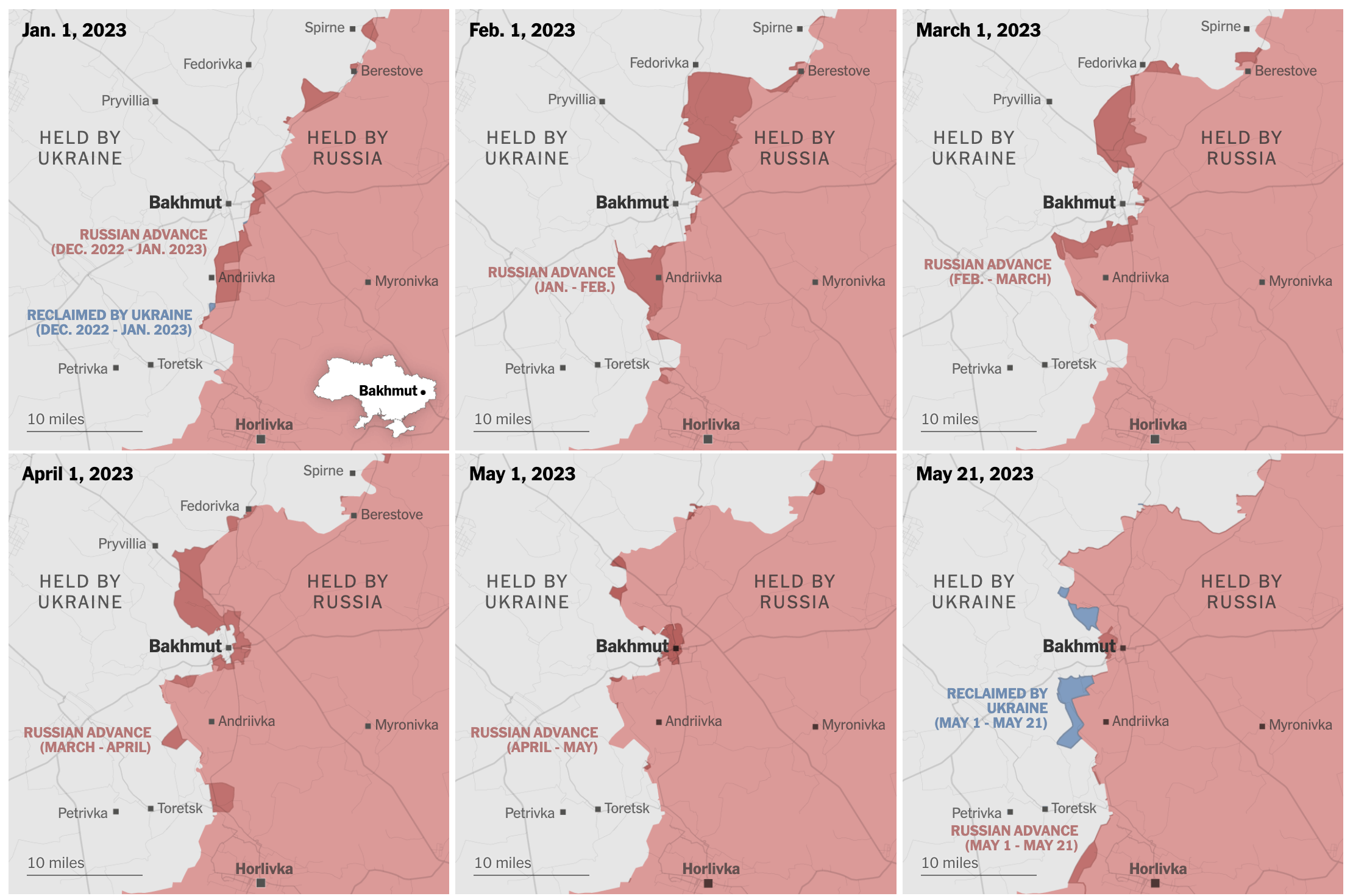
Localizadores 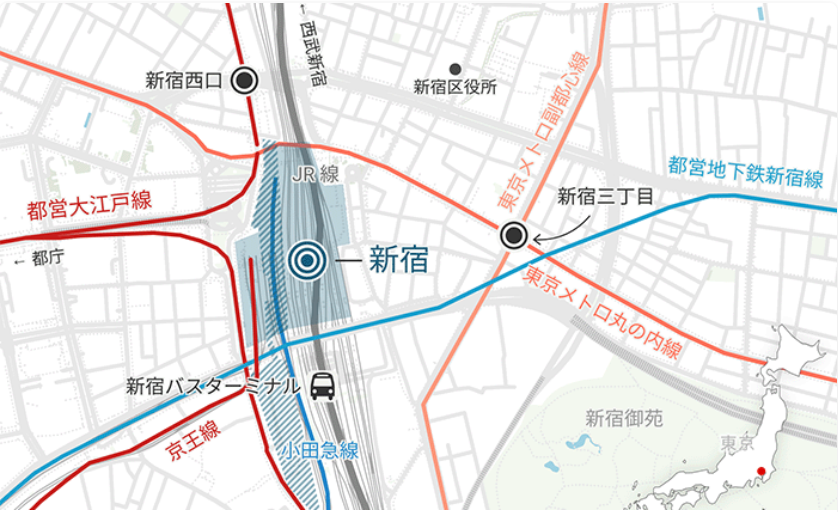
Localizadores o mapas de ubicación
- Los localizadores son mapas estáticos y simples que se usan para ubicar una región concreta en un contexto geográfico
- Ayudan al usuario a familiarizarse con las particularidades de una localización que quizás no conocen de antemano
- Pueden ser muy generales, para explicar la localización de un país en su contexto geográfico, o muy específicos, para ubicar la calle en la que ha ocurrido un suceso y su área circundante

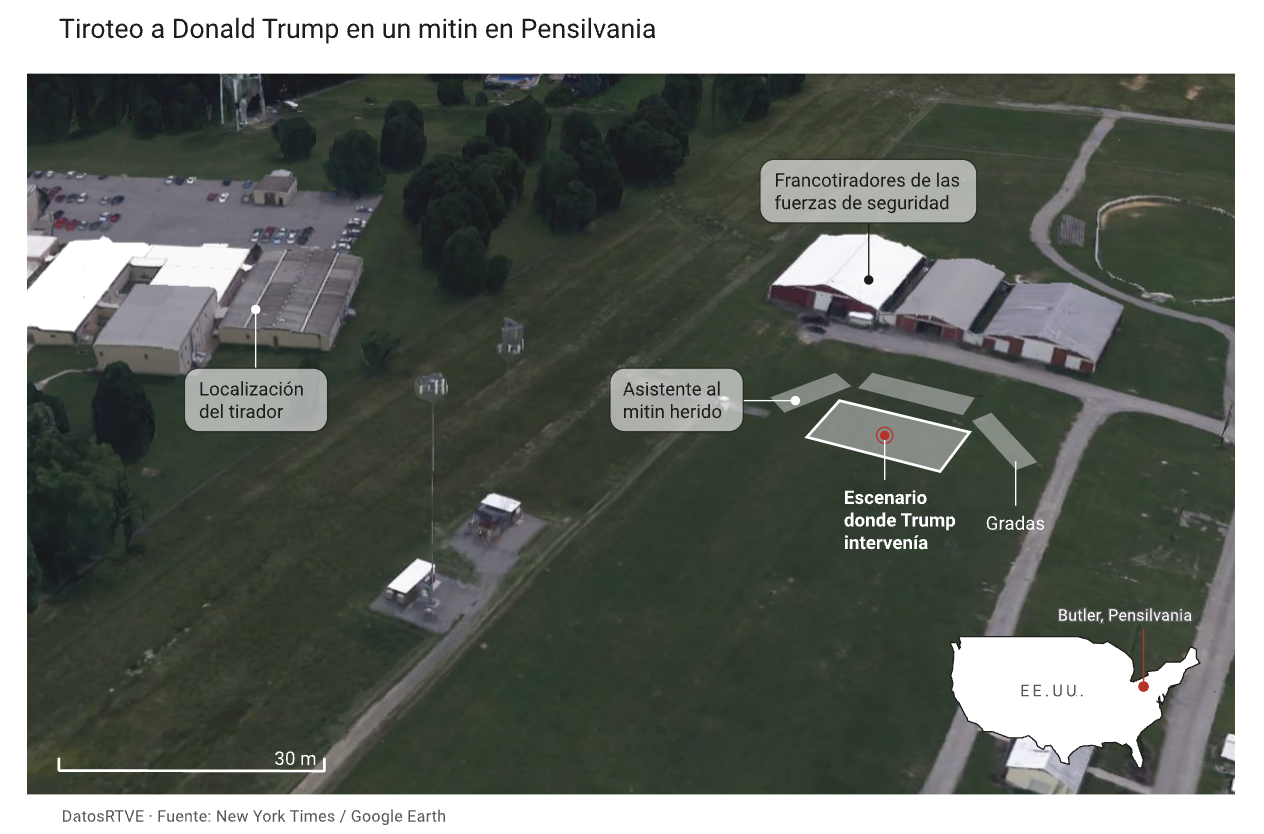
Añade información de referencia
Añade detalles al mapa que ayuden a los usuarios a interpretarlo.
Etiqueta ciudades importantes, calles, mares o ríos que aporten contexto a la historia.
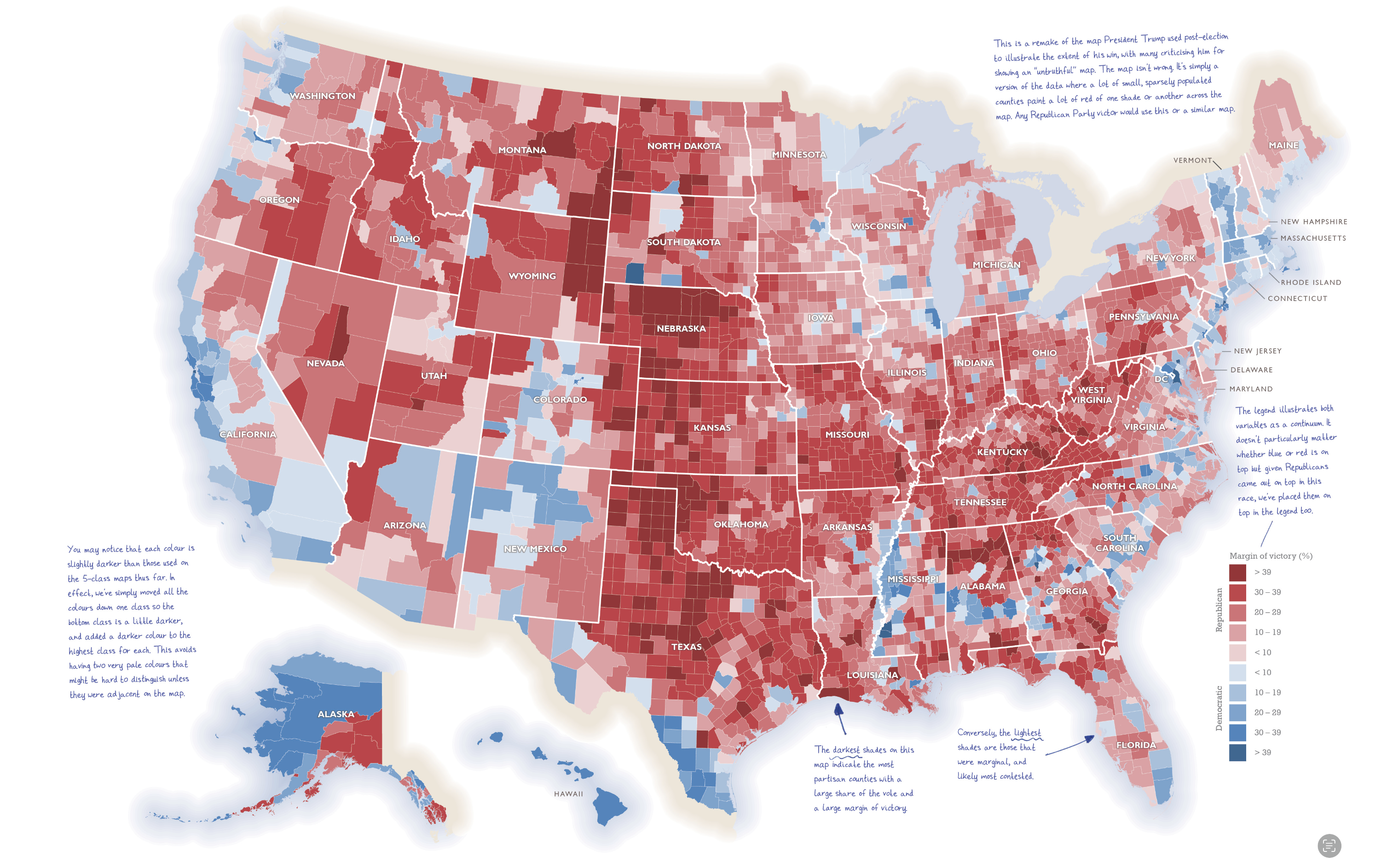
Kenneth Field